Zaman serilerini temsil etmek için Markov bazlı modeller sıkça kullanılır. Genelde istatistiki analiz bağımsız özdeşçe dağılmış (iid) örneklem noktaları olduğunu farz eder, fakat çoğu zaman serisinde veri noktaları birbirinden bağımsız değildir, \(t\) anındaki bir nokta \(t-1\) anındaki nokta ile bağlantılıdır.
Saklı olmayan Markov modellerini, yani Markov Zincirlerini [5]’de görmüştük. Bir MZ sistemi her \(t\) adımında bir konumda (state) olan bir sistem, \(X_1,..,X_T\) rasgele değişkenleri ile temsil edelim, e bu modelde bir konumdan diğerine geçiş belli olasılıklar üzerinden temsil edilir. Hiç değişme olmaması da aslında bir geçiştir, bu durumda konum kendisine doğru bir geçiş yapar. Matematiksel olarak bir konumdan diğerine geçme olasılığı
\[ P(X_t = j | X_{t-1} = i) \]
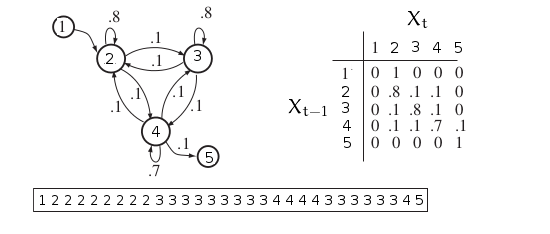
ile gösterilir. Önceki adımda \(i\) konumundayız, geçiş sonrası \(j\)’e geliyoruz, \(t\) anındaki konuma geçiş için sadece \(t-1\)’deki konumu bilmek yeterlidir. Resme bakalım,
Konumlar ayrıksal, üstte 1,2,3 gibi değerler görülüyor. Bu değerler anlamı olan yine ayrıksal bir alfabeyi indisliyor olabilirler. Mesela 1 belki “araba’‘, 2 “bisiklet’‘, 3 “uçak’’ gibi. Geçiş olasılıkları bir \(A\) matrisi içinde toplanabilir, resimde görüldüğü gibi, formülsel olarak
\[ P(X_t = j | X_{t-1} = i) = a_{ij} \]
Resimde ayrıca örnek bir konum serisi / dizisi de görüyoruz. Bu şekilde bir seri bilinen MZ geçiş olasılıklarından “üretilebilir’‘; bir başlangıç konumu seçeriz, bir sonrakine geçiş olasılıklarına bakarız (5 tane), bu olasılıklar üzerinden zar atarız, birini seçeriz, ve o konuma geçeriz. İşlemi tekrarlarız. Böylece \(X_1,X_2,..\) “zincirini’’ elde ederiz.
Tam tersi yönde bir hesap yapmamız da gerekebilir; elde bir seri var, ama \(A\) bilinmiyor, o zaman konum dizisinden \(A\) matrisini “öğrenebiliriz’’. Öğrenim için bildiğimiz maksimum olurluk hesabı kullanılır, herhangi bir konum serisinin olasılığı nedir sorusunun cevabı şu formül;
\[ P(X_1=x_1,..,X_T=x_T) = P(X_1=x_1) \prod_{t=2}^{T} P(X_t=x_t | X_{t-1}=x_{t-1}) \]
Üstteki formül bir olurluk (likelihood) hesabı - \(L(A)\) diyelim,
\[ L(A) = P(X_1=x_1) \prod_{ t=2}^{T} a_{x_{t-1},x_t} \]
Olurluğun maksimize edilmesi ardından \(A\) için bir tahmin edici (estimator) hesaplanabilir - detaylar için [2, Ders 6]; \(n_{ij}\)’yi veri serisinde \(i\)’inci konumdan \(j\)’ye kaç kere geçildiğinin sayısı olarak tanımlarsak, \(A\) tahmin edicisi şöyle olur,
\[ \hat{a}_{ij} = \frac{n_{ij}}{\sum_j n_{ij}} \]
Bu hesap akla yatkın (intuitive) bir sonuç, çünkü \(i\)’den \(j\)’ye geçiş “olasılığını’’ veriden hesaplamak istiyorsak, veride \(i\)’den \(j\)’ye kaç kere geçildiğini sayıp, bu sayıyı yine verideki tüm \(j\)’ye olan geçişlere (hangi konumdan olursa olsun) bölmek bize iyi tahmin sağlar. Bir Gaussian’ın \(\mu\)’sünü tahmin ederken tüm reel veri noktalarını toplayıp bölmek aynı şekilde akla yatkın bir tahmin edicidir.
Şimdi MZ kavramına bir ek daha yapalım. Diyelim ki bir katman daha ekleyeceğiz, öyle ki artık konum geçişlerini dışarıdan göremiyoruz, sadece konumların başka bir dağılıma göre dışarıya ürettiği farklı bir alfabeden değerleri görüyoruz.
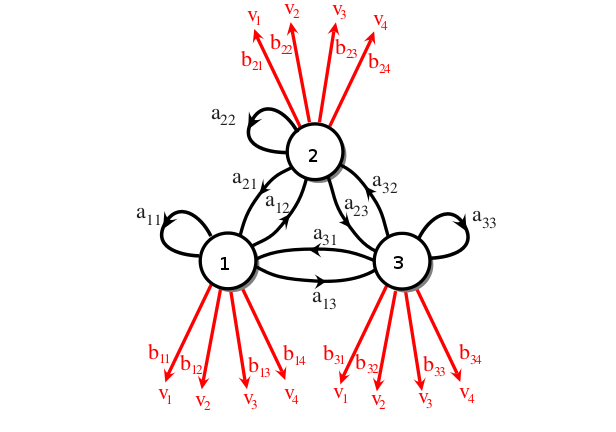
Konum geçişleri bu sayede “saklı’’ hale geldi, ve bir HMM elde ettik. Matris olarak görelim,
\[ A = \left[\begin{array}{rrr} a_{11} & a_{12} & a_{13} \\ a_{21} & a_{22} & a_{23} \\ a_{31} & a_{32} & a_{33} \end{array}\right], \qquad B = \left[\begin{array}{rrrr} b_{11} & b_{12} & b_{13} & b_{14} \\ b_{21} & b_{22} & b_{23} & b_{24} \\ b_{31} & b_{32} & b_{33} & b_{34} \end{array}\right] \]
Üstteki model bir ayrıksal HMM örneğidir, yani hem saklı geçişler ayrıksal (Markov durumunda hep öyle olmak zorunda) ve dışarı üretilen değerler de ayrıksal. Dışarı yansıtılan / salımlanan (emission) sembollerinden 4 tane var, \(v_1,v_2,v_2,v_4\). Salımlar sürekli de olabilirdi, mesela her konumun ayrı bir Gaussian dağılımı olabilirdi. Bu konuya sonra değineceğiz.
Not: Salım sembolleri olarak \(v_1,v_2,..\) kullandık fakat matematik olarak bunlar da aslında bir indis; saklı konumların aynı şekilde tamsayı olan indisleri ile karışmaması için semboller seçildi. Tabii aynen saklı konumda olduğu gibi salımların indisleri de herhangi bir alfabeyi indeksleyebilir. Mesela 1 “a’‘, 2 “b’’ olabilir. İndislerin direk kendisi de kullanılabilir; mesela saklı konumlara bağlı zar atışlarını modelliyorsak salımlar 1,2,3,4,5,6 olacaktır.
Devam edelim; HMM bu salım sembollerinden herhangi birini üretebilir, ama her saklı konumda üretim farklı bir dağılıma göre olur. Bu dağılımları içeren salım olasılıkları ayrı bir \(B\) matrisi üzerinde tutulur. Matrisin boyutu 3 saklı 4 görünen konum üzerinden \(3 \times 4\) olmalıdır, ve matrisin öğeleri \(b_{jk}\)’nin matematiksel tanımı,
\[ b_{jk} = P (V_t = k | X_t = j ) \]
(Görüldüğü gibi üstte salım indisini kullandık). \(V_t\) değişkeni \(t\) anında gizli \(j\) konumunda olan bir HMM’in ürettiği semboldur. İki şarttan bahsetmek lazım şimdi, bunlardan birincisi pür MZ durumunda da geçerli,
\[ \sum_j a_{ij} = 1, \quad \forall i\]
HMM ek bir şart,
\[ \sum_k b_{jk} = 1, \quad \forall j \]
Şimdi diyelim ki \(V\) bir görünen sembol vektörü, \(S_r\) ise \(T\) boyutunda bir saklı konum vektörü, ve bu boyutta olabilecek tüm konum serilerini düşünelim, \(c\) mümkün gizli konum için \(c^T\) tane olur. \(T=6\) için bir vektör \(S_1 = \{1,4,2,2,1,4\}\) gibi.. Şimdi görünen herhangi bir dizinin olasılığını hesaplayalım,
\[ P(V) = \sum_{r}^{c^n} P(V | S_r) P(S_r) \tag{1} \]
Üstteki formüldeki \(P(S_r)\)’in açılımını MZ’lerden zaten biliyoruz,
\[ P(S_r) = \prod_{t=1}^{T}P(X_t|X_{t-1}) \]
Yani gizli konum geçişlerine tekabül eden \(a_{ij}\)’leri bulup onları sırasıyla çarpıyoruz. Üstteki \(\{1,4,2,2,1,4\}\) örneği için bu çarpım \(a_{14}a_{42}a_{22}a_{21}a_{14}\) olurdu.
Ayrıca \(P(V|S_r)\)’in açılımını da biliyoruz,
\[ P(V|S_r) = \prod_{t=1}^{T} P(V_t | X_t) \]
Birleştirelim ve (1)’i genişletelim,
\[ P(V) = \sum_{r}^{c^T} \prod_{t=1}^{T} P(V_t | X_t) P(X_t|X_{t-1}) \]
Formül biraz korkutucu duruyor ama aslında söylediği şu: verilen bir \(V\)’nin olasılığını hesaplamak için tüm mümkün saklı konum dizileri üzerinden bir toplam almalıyız, bu toplamdaki her dizi için \(a_{ij}\) üzerinden gizli geçişlerin çarpımını alırız, sonra görünen salımların bir çarpımını alırız, ki bu bilgi zaten \(b_{jk}\) içinde. \(A,B\) bilindiğine göre tarif edilen işlemler direk yapılabilir.
Fakat bu hesap aşırı yüksek boyutlu bir hesaptır, çetrefilliği \(O(c^T \cdot T)\), mesela \(c=10,T=20\) olsa \(10^{21}\) ölçeğinde bir hesaptan bahsediyoruz. İçinde \(c\) sembol olan bir alfabenin \(n\) uzunluğunda çok fazla farklı dizilimi mümkündür.
İleri Algoritması (Forward Algorithm)
Fakat \(P(V)\)’yi literatürde ileri algoritması denilen bir yöntemle özyineli (recursive) olarak hesaplamak mümkündür. Bakıyoruz her terim $P(V_t | X_t) P(X_t|X_{t-1}) $için sadece \(V_t,X_t,X_{t-1}\) gerekli. O zaman özyineli hesap için yeni bir değişken tanımlarız, bilinen bir model \(\lambda = (A,B)\) için
\[ \alpha_t(i) = P(V_1,V_2,..,V_t, X_t = i; \lambda) \]
Bu gözlenen salım dizisinin sadece bir kısmı üzerinden tanımlanmış bir olasılık; tanıma göre zaman indisi 1’den \(t\)’ye kadar, ve bu en son \(t\) noktasında saklı konum \(i\)’de olmalı. Özyineli tanımı görmek için \(\alpha_1(i)\)’nin ne olduğuna bakalım, notasyon kısalığı için \(\pi_i = P(X_1 = i)\),
\[ \alpha_1(i) = \pi_i b_{i,V_1} \]
Tümevarımsal (induction), özyineli kısım ise şöyle tanımlanır,
\[ \alpha_{t+1}(j) = \bigg[ \sum_{i=1}^{c} \alpha_t(i)a_{ij} \bigg] b_{j,V_{t+1}} \]
Formülün niye performans ilerlemesi getirdiğini görmek için örnek 1,2,3,4 gizli konumların tüm permutasyonlarının düşünelim,
import itertools
l = list(itertools.permutations([1, 2, 3, 4]))[:10]
for x in l: print (x)
print ('...')(1, 2, 3, 4)
(1, 2, 4, 3)
(1, 3, 2, 4)
(1, 3, 4, 2)
(1, 4, 2, 3)
(1, 4, 3, 2)
(2, 1, 3, 4)
(2, 1, 4, 3)
(2, 3, 1, 4)
(2, 3, 4, 1)
...Mesela \(t=2\)’de \(\alpha_2(V_2)\) hesabını düşünelim; bu hesap ilk satırdaki 1,2,.. için bir kere yapılmış olacaktır, 2. satırda bir daha hesaplanması gerekmez. Hatta daha geriye gidersek ilk adımda 1 konumunda olan tüm satırlar da (6 tane) sadece bir kez \(\alpha\) ile hesaplanırlar.
Geri Algoritması (Backward Algorithm)
Benzer şekilde \(\beta_t(i)\) üzerinden bir geri algoritması diye bilinen bir algoritma vardır; bu algoritma ileri versiyonun bir nevi aynadaki yansıması. Bu algoritmada \(t=1\)’den ileri değil, \(T\)’den geriye doğru gitmiş oluyoruz.
\[ \beta_t(i) = P(V_{t+1}, v_{t+2},...,V_{T} | X_t = i ; \lambda ) \]
Bu formül bilinen model \(\lambda\) ve \(t\) anında saklı konum \(i\)’de olma koşuluna göre, \(t+1\)’den en sona kadar olan verili salımların olasılığının hesabını yapar. Özyineli adım,
\[ \beta_T(i) = 1 \]
\[ \beta_t(i) = \sum_{j=1}^{c} a_{ij}b_{j,V_{t+1}} \beta_{t+1}(j) \]
Viterbi Algoritması
Bilinen \(\lambda\) için verili bir \(V\) salımlarına tekabül eden saklı konum geçişlerini bulmak için Viterbi algoritması kullanalım. Detaylara girmeden önce hemen bir örnek görelim [3, sf. 606].
Bir kumarhanede tek zar üzerinden oynanan bir oyunda zarların hileli olduğundan şüphe ediyoruz. Bu problemi HMM ile şu şekilde modelleyebiliriz: bir iyi zar bir de hileli zar var. Bu iki zar iki farklı “saklı’’ konuma tekabül edecekler. Ama biz bu saklı konumları görmüyoruz, sadece zar atışlarının sonucunu görüyoruz.
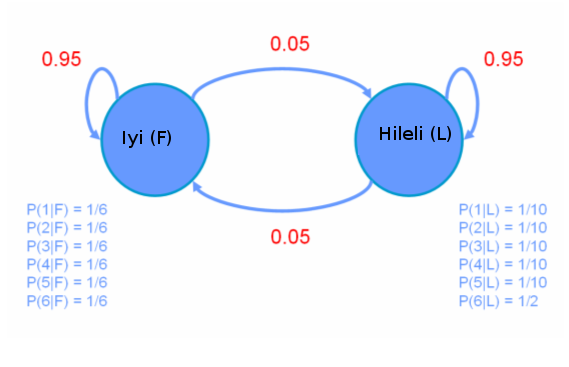
Üstteki modele göre hileli zardan 6 gelme olasılığı (salım olasılığı) daha yüksek. İki saklı konum arasındaki geçiş anormal sayılmaz, “arada sırada’’ birinden bir konumdan diğerine geçiş var, kumarhane”bazen’’ zarları değiştiriyor yani. Şimdi saklı geçişi bulalım,
import dhmm
rolls = [1,2,4,5,5,2,6,4,6,2,1,4,6,1,4,6,1,3,6,1,3,6,\
6,6,1,6,6,4,6,6,1,6,3,6,6,1,6,3,6,6,1,6,3,6,1,\
6,5,1,5,6,1,5,1,1,5,1,4,6,1,2,3,5,6,2,3,4,4]
rolls = np.array(rolls)-1
a = np.array([[0.95, 0.05],[0.05, 0.95]])
b = np.array([[1/6., 1/6., 1/6., 1/6., 1/6., 1/6.],
[1/10.,1/10.,1/10.,1/10.,1/10.,1/2.]])
pi = np.array([0.5, 0.5])
hmm = dhmm.HMM(2,6,pi,a,b)
print (hmm.viterbi_path(rolls))Shape of self.obsmat after init: (2, 6)
Shape of self.transmat after init: (2, 2)
Shape of self.prior after init: (2,)
[0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]Müthiş! Viterbi ile ne zaman hileli, ne zaman düzgün zar kullanıldığını pat diye hesapladık. Kumarhane önce hilesiz başlıyor, ardından zarları değiştiriyor ve uzun süre hile yapıyor.
Algoritmanın nasıl işlediğini anlamak için farklı bir modele bakalım,
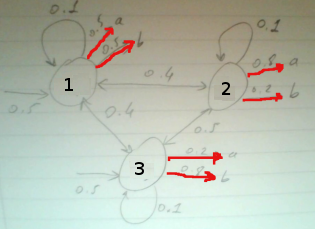
Bu modelde 3 tane saklı konum var, ve salım alfabesi \(a,b\) (tabii kodlama / matematiksel olarak 1,2 olacak). Viterbi algoritmasının işleyişini anlatmak için saklı konumlar ve aralarındaki geçiş zamana doğru sağa doğru yayılacak şekilde resimlenir, bu resme “trellis’’ deniyor.
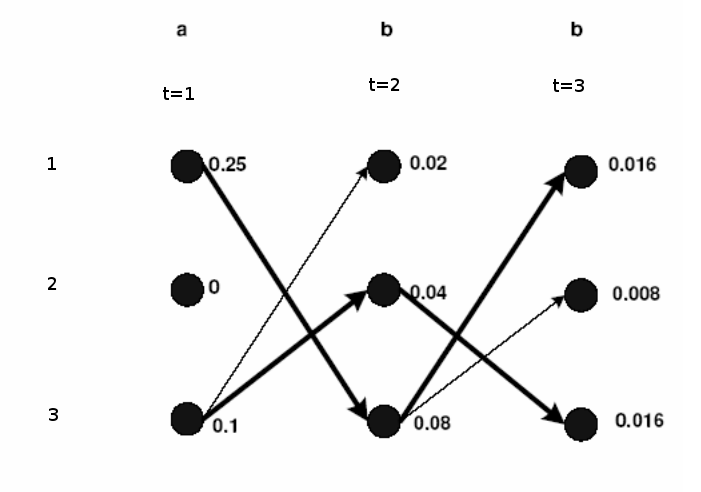
Kısayol algoritması şöyle; üstteki resimde zaman/konum düğümlerine başlangıçtan o noktaya gelmenin olasılığı yazılmış. Yani bu değer o noktanın ne kadar olası olduğunu gösteriyor. Hesabın bir örneği; trellisin ortasından secelim, diyelim ki \(t=1\) anında 3 konumundan 1 konumuna geçmek istiyoruz, bu geçiş sonrası yol ne olur? \(t=1\)’de 3 üzerinde 0.1 diyor, 3-1 geçişinin olasılığı 0.4 çarpı 1 konumundan ‘b’ salımı olasılığı 0.5, o zaman 0.10.40.5 = 0.02. Böylece başla-3-1 yolunun olasılığı 0.02 haline geldi. Bu hesap sağa doğru genişletilir, eğer bir noktaya birden fazla geçiş mümkün ise, nihai hesaplar arasında en yüksek olan seçilir. En sağa geldiğimizde 1’de biten bir 0.016 yolu görüyoruz, bir de 3’de biten bir 0.016 yolu görüyoruz. İki yolun hesabı aynı çıktı, çoğunlukla bu durum olmaz, fakat bu yollardan herhangi birini seçmek, ya da ikisini birden raporlamak problem değildir.
Yolu dhmm’e hesaplatırsak,
import dhmm
a = np.array([[0.1,0.4,0.4],[0.4,0.1,0.5],[0.4,0.5,0.1]])
b = np.array([[0.5,0.5],[0.8,0.2],[0.2,0.8]])
pi = np.array([0.5, 0, 0.5])
hmm = dhmm.HMM(3,2,pi,a,b)
print (hmm.viterbi_path([0,1,1]))Shape of self.obsmat after init: (3, 2)
Shape of self.transmat after init: (3, 3)
Shape of self.prior after init: (3,)
[0 2 0]Eğer 1 ve 3’e en soldan giriş yapan bir başlangıç noktası S, ve en sonda tüm düğümlerin gittiği bir bitiş noktası E hayal edersek, aslında üstteki tarif edilen [6] yazısında anlatılan kısayol algoritmasına benziyor. Elimizde bir yönlü ve çevrimsiz bir çizit (directed, acyclic graph) var, S’den başlıyoruz, sürekli adım atarak arkada bıraktığımız yolun uzunluğunu (bu durumda olasılığını) sürekli toplayarak her adımda hesaplıyoruz, ve hatırlıyoruz (gerçi üstteki örnekte olasılıklar çarpıldı -çünkü o yolun birleşik olasılığı hesaplanmalıydı- fakat log alınıp toplanabilirdi, hatta sayısal stabilite sebepleriyle bu yapılmalıdır). Trellis’teki her geçiş çizitte bir kenar, daha önce kullandığımız örnek \(t=1\) anındaki 3-1 geçişi için kenar 0.4*0.5=0.2. Bu kenarlar takip edilerek bir kısayol bulunacaktır.
Model Öğrenmek, İleri-Geri Algoritması
HMM’in güzellikleri bitmedi; sadece görünen semboller dizisini kullanarak, sadece kaç tane saklı konum olacağını tanımlayarak, tüm HMM modelini öğrenmek mümkün. Yani \(A,B\) matrisleri, ve tabii ki bunu elde edince görünen salımlara tekabül eden saklı geçişleri de hesaplayabilecegiz. Kumarhane örneğine dönelim, yeni bir HMM yaratalım, ve dışarıdan bir model tanımlamadan, onu direk veri ile eğitelim.
a2 = np.array([[0.1,0.4,0.4],[0.2,0.3,0.5],[0.6,0.3,0.1]])
b2 = np.array([[1/6.,1/6.,1/6.,1/6.,1/6.,1/6.],
[1/10.,1/10.,1/10.,1/10.,1/10.,1/2.],
[1/8.,1/8.,1/8.,1/8.,1/8.,1/8.]])
pi2 = np.array([0.5,0.2,0.3])
rolls2 = [1,2,4,5,5,2,6,4,6,2,1,4,6,1,4,6,1,3,6,1,3,6,\
6,6,1,6,6,4,6,6,1,6,3,6,6,1,6,3,6,6,1,6,3,6,1,\
6,5,1,5,6,1,5,1,1,5,1,4,6,1,2,3,5,6,2,3,4,4]
rolls2 = np.array(rolls2)-1
# Add debug prints to confirm the shapes before initialization
print(f"DEBUG: Shape of 'a2' before hmm2 init: {np.shape(a2)}")
print(f"DEBUG: Shape of 'b2' before hmm2 init: {np.shape(b2)}")
print(f"DEBUG: Shape of 'pi2' before hmm2 init: {np.shape(pi2)}")
# Use the new variables for hmm2
hmm2 = dhmm.HMM(3, 6, pi2, a2, b2) # Pass the new variables
print(f"DEBUG: hmm2.prior before train: {hmm2.prior}")
print(f"DEBUG: type(hmm2.prior) before train: {type(hmm2.prior)}")
hmm2.train([rolls2],iter=20) # Use rolls2 here
print (hmm2.viterbi_path(rolls))
print ('aic', hmm2.aic())
print (hmm2.transmat)
print (hmm2.prior)
print (hmm2.obsmat)DEBUG: Shape of 'a2' before hmm2 init: (3, 3)
DEBUG: Shape of 'b2' before hmm2 init: (3, 6)
DEBUG: Shape of 'pi2' before hmm2 init: (3,)
Shape of self.obsmat after init: (3, 6)
Shape of self.transmat after init: (3, 3)
Shape of self.prior after init: (3,)
DEBUG: hmm2.prior before train: [0.5 0.2 0.3]
DEBUG: type(hmm2.prior) before train: <class 'numpy.ndarray'>
dhmm_em: prior at start: [0.5 0.2 0.3]
Shape of emission_matrix at start of dhmm_em: (3, 6)
mk_stochastic input T shape: (3, 3)
mk_stochastic input T content:
[[ 2.0608551 10.14930143 6.99962993]
[ 5.56696363 9.29166847 11.67271293]
[11.43694417 7.20878736 1.61313697]]
mk_stochastic input T shape: (3, 6)
mk_stochastic input T content:
[[ 5.5321326 1.70482453 2.6112982 3.05089483 2.54744945 4.16575774]
[ 4.03268235 1.39589882 1.80014433 2.09477351 1.94254 15.53649922]
[ 6.43518505 1.89927665 2.58855747 2.85433166 2.51001055 4.29774304]]
mk_stochastic input T shape: (3, 3)
mk_stochastic input T content:
[[ 2.01274751 10.38353432 6.76968643]
[ 5.71038183 8.90613699 11.93280042]
[11.26803967 7.44393405 1.57273878]]
mk_stochastic input T shape: (3, 6)
mk_stochastic input T content:
[[ 5.31424165 1.63967966 2.7129312 3.2173627 2.59484706 4.07641105]
[ 3.73071271 1.48366009 1.71887708 2.05299984 2.06193754 15.77638965]
[ 6.95504563 1.87666025 2.56819171 2.72963746 2.34321541 4.1471993 ]]
mk_stochastic input T shape: (3, 3)
mk_stochastic input T content:
[[ 1.94791604 10.71383697 6.40892947]
[ 5.82544627 8.4710943 12.30948197]
[11.14911624 7.64772506 1.52645367]]
mk_stochastic input T shape: (3, 6)
mk_stochastic input T content:
[[ 5.03832912 1.60417404 2.82697522 3.41240522 2.6629127 3.92576965]
[ 3.34020723 1.59127772 1.60575796 1.97852206 2.21388838 16.15190195]
[ 7.62146366 1.80454824 2.56726682 2.60907272 2.12319892 3.9223284 ]]
mk_stochastic input T shape: (3, 3)
mk_stochastic input T content:
[[ 1.86137074 11.18179807 5.87912151]
[ 5.88778705 7.96943652 12.85094034]
[11.09583731 7.80792343 1.46578503]]
mk_stochastic input T shape: (3, 6)
mk_stochastic input T content:
[[ 4.63598248 1.60487291 2.9591339 3.66039413 2.75789403 3.71631438]
[ 2.86351266 1.72468564 1.45265212 1.86183664 2.40261456 16.67642115]
[ 8.50050485 1.67044145 2.58821399 2.47776924 1.83949141 3.60726446]]
mk_stochastic input T shape: (3, 3)
mk_stochastic input T content:
[[ 1.74293302 11.8108341 5.14865938]
[ 5.84532671 7.3940254 13.61205411]
[11.16220098 7.90819602 1.37577028]]
mk_stochastic input T shape: (3, 6)
mk_stochastic input T content:
[[ 4.03877853 1.6448022 3.11622193 3.98750275 2.88247814 3.46066271]
[ 2.30400457 1.88755829 1.25238125 1.69326258 2.62831558 17.35574026]
[ 9.6572169 1.4676395 2.63139682 2.31923467 1.48920627 3.18359704]]
mk_stochastic input T shape: (3, 3)
mk_stochastic input T content:
[[ 1.58360272 12.57543931 4.24722894]
[ 5.62600798 6.77103755 14.61902046]
[11.41348554 7.93339507 1.23078242]]
mk_stochastic input T shape: (3, 6)
mk_stochastic input T content:
[[ 3.23259891 1.70479951 3.29553084 4.40078041 3.02005885 3.20034636]
[ 1.69031736 2.08006125 1.00794374 1.47435347 2.88130523 18.14793067]
[11.07708373 1.21513924 2.69652542 2.12486612 1.09863592 2.65172297]]
mk_stochastic input T shape: (3, 3)
mk_stochastic input T content:
[[ 1.39736004 13.34730545 3.30777234]
[ 5.19968287 6.19805543 15.79643496]
[11.82815976 7.91313106 1.01209807]]
mk_stochastic input T shape: (3, 6)
mk_stochastic input T content:
[[ 2.35442829 1.72067762 3.45857978 4.84102207 3.11904076 3.02862928]
[ 1.11061999 2.31210443 0.74571881 1.23691043 3.14461607 18.90881137]
[12.53495172 0.96721795 2.79570141 1.9220675 0.73634318 2.06255935]]
mk_stochastic input T shape: (3, 3)
mk_stochastic input T content:
[[ 1.23502957 13.93024081 2.48000049]
[ 4.64107338 5.80917657 16.97082252]
[12.228385 7.95243633 0.75283533]]
mk_stochastic input T shape: (3, 6)
mk_stochastic input T content:
[[ 1.64028997 1.60743429 3.52341042 5.18007963 3.12341856 3.05681146]
[ 0.68218777 2.62027211 0.50828624 1.03648827 3.40836454 19.4362755 ]
[13.67752227 0.7722936 2.96830334 1.7834321 0.46821689 1.50691304]]
mk_stochastic input T shape: (3, 3)
mk_stochastic input T content:
[[ 1.13538401 14.24701768 1.80210542]
[ 4.04525265 5.61248984 18.03155017]
[12.48396931 8.11845782 0.5237731 ]]
mk_stochastic input T shape: (3, 6)
mk_stochastic input T content:
[[ 1.20294197 1.33644821 3.43394889 5.33586642 3.04221529 3.31851936]
[ 0.4364618 3.03090392 0.3186357 0.89943362 3.66104715 19.63148391]
[14.36059623 0.63264787 3.24741541 1.76469997 0.29673756 1.04999672]]
mk_stochastic input T shape: (3, 3)
mk_stochastic input T content:
[[ 1.08942932 14.3934306 1.2496213 ]
[ 3.44400889 5.46914975 18.98087385]
[12.66599916 8.34899537 0.35849176]]
mk_stochastic input T shape: (3, 6)
mk_stochastic input T content:
[[ 0.99762606 0.96870382 3.21648409 5.32291744 2.94127617 3.75330246]
[ 0.31366284 3.50046026 0.17789374 0.80821705 3.87372521 19.53761664]
[14.6887111 0.53083592 3.60562217 1.86886551 0.18499862 0.7090809 ]]
mk_stochastic input T shape: (3, 3)
mk_stochastic input T content:
[[ 1.07074123 14.48674745 0.82106024]
[ 2.84425871 5.25432577 19.83019016]
[12.91046472 8.53652536 0.24568636]]
mk_stochastic input T shape: (3, 6)
mk_stochastic input T content:
[[ 0.93176054 0.60950432 2.9507612 5.18546385 2.8789615 4.26915086]
[ 0.24970889 3.92564219 0.08576928 0.74022427 4.01576209 19.26049185]
[14.81853056 0.46485349 3.96346952 2.07431188 0.10527641 0.47035729]]
mk_stochastic input T shape: (3, 3)
mk_stochastic input T content:
[[ 1.06305667 14.58346196 0.52371086]
[ 2.26045807 4.94191824 20.56552993]
[13.27920869 8.61585332 0.16680228]]
mk_stochastic input T shape: (3, 6)
mk_stochastic input T content:
[[ 0.92793708 0.33366752 2.71747066 4.96632416 2.87513034 4.78221689]
[ 0.20921305 4.21988516 0.0361133 0.69021981 4.07555129 18.91025089]
[14.86284987 0.44644732 4.24641604 2.34345603 0.04931837 0.30753222]]
mk_stochastic input T shape: (3, 3)
mk_stochastic input T content:
[[ 1.06125837 14.6955677 0.33787771]
[ 1.7256606 4.57183783 21.1743683 ]
[13.72733542 8.59451662 0.11157745]]
mk_stochastic input T shape: (3, 6)
mk_stochastic input T content:
[[9.38866269e-01 1.56415810e-01 2.55630851e+00 4.72103092e+00
2.91237161e+00 5.22926561e+00]
[1.78911906e-01 4.36109296e+00 1.39085188e-02 6.63992623e-01
4.07056351e+00 1.85734526e+01]
[1.48822218e+01 4.82491228e-01 4.42978297e+00 2.61497646e+00
1.70648825e-02 1.97281757e-01]]
mk_stochastic input T shape: (3, 3)
mk_stochastic input T content:
[[ 1.06090965 14.81858953 0.22664149]
[ 1.28886402 4.18881376 21.65635387]
[14.1565464 8.52920036 0.07408093]]
mk_stochastic input T shape: (3, 6)
mk_stochastic input T content:
[[9.45157989e-01 6.00508937e-02 2.46572782e+00 4.50367165e+00
2.95698853e+00 5.57472406e+00]
[1.55454310e-01 4.37236748e+00 5.14804459e-03 6.64064211e-01
4.03900221e+00 1.83005674e+01]
[1.48993877e+01 5.67581629e-01 4.52912414e+00 2.83226414e+00
4.00925371e-03 1.24708538e-01]]
mk_stochastic input T shape: (3, 3)
mk_stochastic input T content:
[[ 1.05389707 14.94573433 0.15853434]
[ 0.98035425 3.82207711 22.02381495]
[14.49576928 8.47048363 0.04933505]]
mk_stochastic input T shape: (3, 6)
mk_stochastic input T content:
[[9.45888767e-01 1.80895028e-02 2.43058060e+00 4.33316572e+00
2.98498069e+00 5.81731552e+00]
[1.37431098e-01 4.29594254e+00 1.89790667e-03 6.85579319e-01
4.01439093e+00 1.81030533e+01]
[1.49166801e+01 6.85967961e-01 4.56752149e+00 2.98125496e+00
6.28378173e-04 7.96312118e-02]]
mk_stochastic input T shape: (3, 3)
mk_stochastic input T content:
[[ 1.03206432 15.07399949 0.11436162]
[ 0.7906072 3.4874602 22.30048809]
[14.7338035 8.43408328 0.03313231]]
mk_stochastic input T shape: (3, 6)
mk_stochastic input T content:
[[9.46281121e-01 4.25309467e-03 2.43648867e+00 4.19604237e+00
2.99170331e+00 5.98170649e+00]
[1.22935541e-01 4.17730381e+00 7.12275894e-04 7.21127708e-01
4.00822713e+00 1.79652365e+01]
[1.49307833e+01 8.18443092e-01 4.56279905e+00 3.08282992e+00
6.95618190e-05 5.30570110e-02]]
mk_stochastic input T shape: (3, 3)
mk_stochastic input T content:
[[9.89935230e-01 1.52070370e+01 8.40204024e-02]
[6.90463281e-01 3.18452397e+00 2.25133755e+01]
[1.48956551e+01 8.41260214e+00 2.23872731e-02]]
mk_stochastic input T shape: (3, 6)
mk_stochastic input T content:
[[9.49711911e-01 8.05873456e-04 2.47114058e+00 4.07254549e+00
2.98411660e+00 6.09773322e+00]
[1.10031350e-01 4.04844206e+00 2.75275153e-04 7.64943827e-01
4.01587751e+00 1.78645931e+01]
[1.49402567e+01 9.50752066e-01 4.52858414e+00 3.16251068e+00
5.88809207e-06 3.76736558e-02]]
mk_stochastic input T shape: (3, 3)
mk_stochastic input T content:
[[9.24079275e-01 1.53530792e+01 6.23095154e-02]
[6.55067290e-01 2.89818625e+00 2.26856772e+01]
[1.50113266e+01 8.39517713e+00 1.50975689e-02]]
mk_stochastic input T shape: (3, 6)
mk_stochastic input T content:
[[9.56731487e-01 1.29019708e-04 2.52485805e+00 3.95038318e+00
2.97012757e+00 6.18824383e+00]
[9.74718776e-02 3.92254143e+00 1.09941372e-04 8.13346489e-01
4.02987203e+00 1.77831009e+01]
[1.49457966e+01 1.07732955e+00 4.47503201e+00 3.23627033e+00
4.02725113e-07 2.86553089e-02]]
mk_stochastic input T shape: (3, 3)
mk_stochastic input T content:
[[8.32135053e-01 1.55220651e+01 4.63712945e-02]
[6.70980001e-01 2.60503177e+00 2.28350535e+01]
[1.51034152e+01 8.37490033e+00 1.00476284e-02]]
mk_stochastic input T shape: (3, 6)
mk_stochastic input T content:
[[9.66796955e-01 1.82908085e-05 2.59155022e+00 3.82447135e+00
2.95440729e+00 6.26928618e+00]
[8.47641029e-02 3.80042268e+00 4.52806644e-05 8.63674804e-01
4.04559269e+00 1.77074977e+01]
[1.49484389e+01 1.19955903e+00 4.40840450e+00 3.31185384e+00
2.28394974e-08 2.32161219e-02]]
mk_stochastic input T shape: (3, 3)
mk_stochastic input T content:
[[7.13148971e-01 1.57250243e+01 3.44745828e-02]
[7.34117802e-01 2.27841244e+00 2.29737620e+01]
[1.51876432e+01 8.34690848e+00 6.50827202e-03]]
mk_stochastic input T shape: (3, 6)
mk_stochastic input T content:
[[9.79380303e-01 2.39736990e-06 2.66843995e+00 3.69367047e+00
2.93929592e+00 6.35412091e+00]
[7.18940550e-02 3.67826440e+00 1.91283254e-05 9.13374301e-01
4.06070408e+00 1.76260893e+01]
[1.49487256e+01 1.32173320e+00 4.33154093e+00 3.39295523e+00
1.07652183e-09 1.97898248e-02]]
[0 0 1 2 0 2 0 1 2 1 2 0 2 1 2 0 1 2 0 1 2 0 1 1 1 2 1 1 2 1 1 2 1 2 1 1 2
1 2 1 1 2 1 2 1 2 1 2 0 2 1 2 0 2 0 1 2 0 1 2 0 2 0 1 1 2 0]
aic 244.32189063865465
[[0.1 0.4 0.4]
[0.2 0.3 0.5]
[0.6 0.3 0.1]]
[0.5 0.2 0.3]
[[0.16666667 0.16666667 0.16666667 0.16666667 0.16666667 0.16666667]
[0.1 0.1 0.1 0.1 0.1 0.5 ]
[0.125 0.125 0.125 0.125 0.125 0.125 ]]Saklı konum geçişleri aynı çıktı! Gerçi eğitimi birkaç kez işletmek gerekti, çünkü HMM eğitimi bir tür Beklenti-Maksimizasyon (Expectation-Maximization -EM-) algoritması kullanır, ve bu algoritmanın yerel maksimada takılıp kalması mümkündür, o yüzden birkaç kez işlettik, ve AIC’si en düşük olanı seçtik. Fakat bu zaten EM kullanıldığında uygulanması tavsiye edilen bir tekniktir.
Detaylara inmeden önce formülsel olarak, bize verili bir \(V\) dizisi bağlamında \(t\) anında \(i\) konumunda olmanın olasılığı lazım; yani \(P(X_t = i | V; \lambda)\). Bu formüle nasıl erişiriz? \(X_t = i\) ile \(V\)’nin birleşik dağılımını düşünelim (\(\lambda\)’yi kalabalık olmasın diye göstermiyoruz), onu \(V\)’leri ortadan bölerek iki parçalı olarak gösterebiliriz,
\[ P(X_t = i, V) = P( V_1,V_2,..,V_t,X_t=i) P (V_{t+1},V_{t+2},..,V_T | X_t=i ) \]
Eşitliğin sağ tarafındaki ilk kısım \(\alpha\) ikinci kısım \(\beta\) değil mi? Evet. O zaman
\[ = \alpha_t(i) \beta_t(i) \]
Fakat hala \(V\)’nin verili olduğu hali elde etmedik, onun için bir bölüm lazım. Bölümü yapalım ve sonuca yeni bir sembol verelim,
\[ \gamma_t(i) \equiv P(X_t = i | V) = \frac{P(X_t = i, V) }{P(V)} = \frac{\beta_t(i)\alpha_t(i)}{ P(V)} \]
Bu noktada, teorik olarak,
\[ \underset{argmax}{1 \le i \le c} [ \gamma_t(i) ] \]
çözümü, yani \(t\) anında \(\gamma_t(i)\) maksimize edecek en iyi \(X_t\) konumunu bulmak ve bunu tüm \(t\)’ler için yapmak bize verili \(V\) için en optimal saklı yolu verir diye düşünebilirdik, fakat üstteki ifade teker teker konumlara bakıyor, ve geçişleri gözönüne almıyor. Bunun için Viterbi algoritması hala en iyi çözüm. Detaylar için [1]. Her halükarda, üstteki ifade bize eğitim için yardımcı olacak.
Devam edelim, \(\xi\)’i tanımlayalım,
\[ \xi_t(i,j) = P(X_t = i, X_{t+1}= j | V; \lambda) \tag{2} \]
\(\xi\) ile \(t\) anında \(i\) konumunda \(t+1\) anında \(j\) konumunda olma olasılığını tanımlamış oluyoruz. Üstteki ifadeyi
\[ = \frac{\alpha_t(i)a_{ij}b_{j,V_{t+1}}\beta_{t+1}(j) }{P(V;\lambda)}\]
olarak yazabiliriz, ve
\[ = \frac{\alpha_t(i)a_{ij}b_{j,V_{t+1}}\beta_{t+1}(j) } {\sum_{i=1}^{c}\sum_{j=1}^{c} \alpha_t(i)a_{ij}b_{j,V_{t+1}}\beta_{t+1}(j) } \]
Bölendeki ifade bölünendeki ifadenin tüm \(i,j\) üzerinden alınan toplamının geriye sadece \(P(V;\lambda)\) bırakacak olmasından ileri geliyor, çünkü (2)’den hareketle bölünendeki ifade \(P(X_t = i, X_{t+1}= j, V; \lambda)\).
\(\gamma_t(i)\)’yi daha önce \(V\)’nin verildiği ve \(\lambda\) modeli bilindiği durumda \(t\) anındaki saklı konum \(i\)’de olmak diye açıklamıştık. O zaman \(\gamma_t(i)\) ve \(\xi_t(i,j)\) arasında bir ilişki kurabiliriz,
\[ \gamma_t(i) = \sum_{j=1}^{c} \xi_t(i,j) \]
Eğer \(\gamma_t(i)\)’nin tüm \(t\)’ler üzerinden toplamını alırsak, bu hesap tüm zamanlar için \(i\) konumunda olmanın, ya da \(i\) konumundan başka herhangi bir konuma geçmiş olmanın beklentisi olarak görülebilir (tabii en son zaman indisi \(T\)’yi bu durumda toplamdan çıkartmak lazım, çünkü o noktadan başka bir noktaya geçmek mümkün değil). Aynı şekilde \(\xi_t(i,j)\)’nin \(t=1,..,T-1\) üzerinden toplamını almak, bize konum \(i\) ve \(j\) arasındaki tüm geçişlerin beklentisini verebilir.
\[ \sum_{t=1}^{T-1} \gamma_t(i) = \textrm{ i'den başka bir konuma geçiş beklentisi} \]
\[ \sum_{t=1}^{T-1} \xi_t(i,j) = \textrm{ i'den j'ye geçiş beklentisi} \]
Üstteki formülleri kullanarak HMM’in parametreleri \(\lambda = (\pi,A,B)\)’yi tahminsel hesaplamak mümkündür.
\[ \overline{\pi} = \textrm{t=1 anında i konumunda olma frekansı} = \gamma_1(i) \tag{3} \]
\[ \overline{a_{ij}} = \frac{\textrm{i konumundan j konumuna geçiş beklentisi}} {\textrm{i konumundan başka herhangi bir konuma geçişin beklentisi}} \]
\[ = \frac{ \sum_{t=1}^{T-1}\xi_t(i,j) }{ \sum_{t=1}^{T-1} \gamma_t(i) } \tag{4} \]
\[ \overline{b_{j,k}} = \frac{\textrm{j konumunda olup } v_k \textrm{ sembolunu görmüş olmanın beklentisi}} {j \textrm{ konumunda olmanın beklentisi} } \]
\[ = \frac{\sum_{t=1}^{T-1} \gamma_t(j) 1(V_t=k) }{\sum_{t=1}^{T-1}\gamma_t(j) } \tag{5} \]
Tüm bunları kullanarak eğitim yaklaşımını şöyle belirleyebiliriz: bir \(\lambda=(\pi,A,B)\) modeli ile başla, ki başlangıç model rasgele değerler ile bile tanımlanmış olabilir. Ardından formüller (3,4,5)’i kullanarak \(\overline{\pi},\overline{a_{ij}}\) ve \(\overline{b_{j,k}}\)’yi hesapla. Bu hesap ardından Baum ve arkadaşları tarafından ispatlanmıştır ki [1] \(P(V;\overline{\lambda}) > P(V;\lambda)\), yani yeni hesaplanan model veriyi eskisinden daha iyi açıklayacaktır. O zaman üstteki hesapları yeni hesaplanan \(\overline{\lambda}\) ile tekrarlarsak, tekrar daha iyi bir model elde ederiz. Bunu ardı ardına yaparsak en optimal modele erişmiş oluruz. Bu yaklaşım aslında bir Beklenti-Maksimizasyon’dur (EM). Karışım modellerinde olduğu gibi akılda tutmak gerekir ki EM lokal maksima’yı bulur, eğer bu maksimum nokta global (tüm modelin) maksimumu değil ise yanlış bir noktada takılıp kalmış olabilir. Bu yüzden standart tekniği burada da kullanıyoruz, farklı rasgele başlangıç noktalarından başlatıp en iyi olurluğu rapor eden modeli nihai model olarak seçeriz.
Sürekli Salımlar (Continuous Emissions)
Şimdiye kadar gördüğümüz ayrıksal HMM’ler her konumunda farklı bir ayrıksal dağılıma göre zar atıyordu. A,B,C konumları olsun, A konumundan ayrıksal dağılım \(\left[\begin{array}{ccc} 0.2 & 0.5 & 0.3 \end{array}\right]^T\)’a göre zar atıyor olabiliriz, B konumunda farklı bir ayrıksal dağılım \(\left[\begin{array}{ccc} 0.4 & 0.5 & 0.1 \end{array}\right]^T\)’e göre zar atıyor olabiliriz.
Fakat HMM matematiği ayrıksal dağılımlar ile kısıtlı değildir. Her konumun salım dağılımının ayrıksal olduğu gibi sürekli olması da mümkündür.
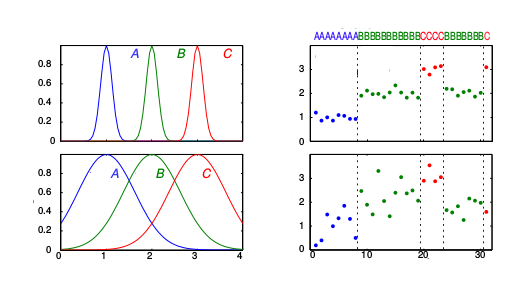
Üstteki resimde iki tane HMM gösteriyoruz, A,B,C diye tanımlı 3 konum var (üst sıra bir HMM, alt sıra bir diğeri). Bu modele göre her konumda farklı olan salım dağılımı ayrıksal değil, bir Gaussian. Mesela 1. HMM için A konumunun mavi renkle gösterilen tek boyutlu bir Gaussian dağılımı var (sol üst köşe), bu Gaussian \(\mu=1\) üzerinden tanımlı, yeşil olan \(\mu=2\), vs. 1. HMM için örnek bir sürekli salım zinciri üst sağ köşedeki gibi olabilir. Bir blokta 1 değeri etrafında bazı değerler görüyoruz, ardından 2 etrafında bir blok, sonra 3, sonra 2, böyle devam ediyor. Bu salım değerlerine bakarak bir HMM’i eğitip hangi konumda hangi Gaussian olduğunu ve konumlar arası geçiş olasılıklarını öğrenebiliriz! Resimde alt sırada farklı Gaussian’lar ve (tabii ki) daha farklı salım zinciri var (saklı geçiş zinciri aynı, ki bu durum modele uygun, fakat saklı zincir biraz daha farklı da olabilirdi).
Sürekli dağılım bazlı HMM matematiği biraz daha farklı, bu konunun detayları için [3, sf. 603].
Kodlar dhmm.py.
Kaynaklar
[1] Rabiner, A Tutorial on Hidden Markov Models and Selected Applications in Speech Recoognition
[2] Shalizi, Statistics, Chaos, Complexity and Inference Lecture
[3] Murphy, Machine Learning, A Probabilistic Perspective
[4] Zuccini, Hidden Markov Models for Time Series
[5] Bayramlı, Lineer Cebir, Ders 21
[6] Bayramlı, Bilgisayar Bilim, Dinamik Programlama