“Her optimizasyon problemi kılık değiştirmiş bir sonsal örnekleme problemidir” denebilir mi? Bu kışkırtıcı kavramsal bir iddia olurdu. Katı matematiksel açıdan bakıldığında bu bir sezgisel kural, ancak teorik fizik ve Bayes istatistik perspektifinden son derece isabetlidir. Matematiksel köprü / argümanın özü Gibbs / Boltzmann dağılımında yatmaktadır. Optimizasyonda, \(f(x)\)’i minimize eden \(x^*\)’i bulmak isteriz. Örneklemede ise bir olasılık dağılımı \(p(x)\)’ten örnekler çekmek isteriz. Herhangi bir optimizasyon problemini, bir dağılım tanımlayarak örnekleme problemine dönüştürmek mümkün:
\[p(x) \propto \exp\left(\frac{f(x)}{T}\right)\]
Burada \(T\)’ye “sıcaklık” parametresi ismi verilir, sıcaklık değiştikça \(f(x)\) ve \(p(x)\) arasındaki bazı tür benzerlikler artar / azalır, bunları yazının devamında işleyeceğiz.
Başka bir deyişle, optimizasyonda şunu bulmak isteriz: \[x^* = \arg\min f(x)\]
Örneklemede ise bir dağılımdan örneklemler almak isteriz:
\[p(x) = \frac{1}{Z} \exp\left(-\frac{f(x)}{T}\right)\]
burada \(Z\) bölüşüm fonksiyonu (normalleştirme sabiti) ve \(T\) daha once belirttigimiz gibi “sıcaklık”.
\(T\) yüksek olduğunda: Dağılım düzdür; örnekleme, manzara üzerinde rastgele bir yürüyüş gibidir.
\(T\) düşük olduğunda: Dağılım, \(f(x)\)’in zirveleri etrafında yoğun biçimde yığılır.
\(T \to 0\) iken: Dağılım, tam olarak \(f(x)\)’in küresel maksimumu üzerinde ortalanmış bir Dirac delta fonksiyonuna (ya da bunların bir kümesine) çöker. Olasılık kütlesi tamamen \(f(x)\)’in küresel minimumu üzerinde yoğunlaşır.
Dolayısıyla \(f(x)\)’in küresel optimumunu bulmak, sıcaklık sıfıra giderken \(p(x)\) sonsal dağılımından örneklemeyle matematiksel olarak eşdeğerdir. \(T \to 0\) limitinde, sonsal dağılımdan örnekleme, küresel optimumu bulmakla eşdeğer hale gelir. Bu nedenle, bir optimizasyon problemi, sıcaklığın mutlak sıfıra itildiği bir örnekleme problemi olarak görülebilir. Eh, herhangi bir dağılımdan örneklem almanın da pek çok yöntemi olduğuna göre (Metropolis, Gibbs örneklem alma, hatta Parcaçık Filtreleri) optimizasyon problemlerini ikiz problemi üzerinden çözmek mümkündür.
Bu yalnızca teorik bir merak konusu değil; birçok önemli algoritmanın temeli:
Simule Edilen Yumuşatma (Simulated Annealing): Bu teknik tanımı bağlamında Gibbs dağılımından örnekleme ve sistemi küresel optimuma “dondurarak” yavaş yavaş \(T\)’yi düşürme süreci, yani tıpatıp üstte tarif ettiğimiz yaklaşım. Bu arada “annealing” metalurjiden gelen bir kavram.
SGLD (Stokastik Gradyan Langevin Dinamiği): Bu, Stokastik Gradyan İnişi (SGD) ile Langevin Dinamiği arasında bir melezdir. SGD’nin özünde bir örnekleme algoritması olduğunu, mini gruplardan kaynaklanan “gürültünün” sıcaklık görevi görerek modelin yerel minimumlara takılmasını engellediğini gösterir.
Optimizasyonu örnekleme olarak görmek çeşitli avantajlar sunar:
Yerel Optimumlardan Kaçmak: Saf optimizasyon (Gradyan İnişi gibi) “açgözlüdür” ve yerel minimumlara takılır. Örnekleme ise “keşifçidir.” Optimizasyonu örnekleme olarak ele alarak, algoritmanın yetersiz çukurlardan “kaçmasını” sağlayan rastlantısallık katarız. Örnekleme, teorik olarak tüm manzarayla ilgilenir. Bir örnekleme yaklaşımı, açgözlü bir optimizasyon yaklaşımına kıyasla yerel minimumlara karşı temelden daha dayanıklıdır.
Belirsizlik Nicelemesi: Optimizasyon size tek bir nokta (en “iyi” cevap) verir. Örnekleme ise bir dağılım verir. Sonsal dağılım optimum etrafında “düz”se, bu size pek çok farklı çözümün en iyisine yakın olduğunu söyler; bu da model sağlamlığını anlamak için hayati önem taşır. Bir sonsal dağılımın güvenlik aralıklarını hesaplayabiliriz. Nihai tek nokta ile yapacak fazla bir şey yoktur.
Düzenlileştirme (Regularization): Örnekleme bakış açısında, önsel dağılım bir düzenlileştirici görevi görür. Ağırlık azalmasıyla (\(\ell_2\) düzenlileştirme) yapılan optimizasyon, Gaussian önselliği üzerinden MAP tahmini bulmakla zaten tamamen aynıdır.
Bir fonksiyonu olasılık yoğunluğuna çevirmek için niye \(\exp\) kullandık? Bazı sebepler var.
Negatif Olmama: \(e^{-f(x)}\) üstel fonksiyonu, herhangi bir gerçek değerli maliyeti kesinlikle pozitif bir değere eşler ve böylece bir olasılık yoğunluk fonksiyonunun ilk gereksinimini karşılar.
Sıra Korunumu: Üstel fonksiyon monotonsal (ya hep artış, ya da hep azalış) olduğundan, tercüme ettiği fonksiyonun göreli sıralamasını korur. Eğer \(f(x_1) < f(x_2)\) ise, o zaman \(e^{-f(x_1)} > e^{-f(x_2)}\). Bu, fonksiyonunuzun küresel minimumunun dağılımınızın modu (en yüksek noktası) olmaya devam etmesini sağlar.
Boltzmann dağılımı, varsayabileceğimiz en “dürüst” dağılımdır. Belirli bir beklenen maliyete \(\langle f \rangle\) sahip olan ancak bunun dışında mümkün olduğunca tarafsız olan bir olasılık dağılımı bulmak istiyorsanız, Maksimum Entropi İlkesi çözümün şu formu alması gerektiğini kanıtlar: \(P(x) \propto \exp(-\beta f(x))\). \(\exp\) kullanmak, amaç fonksiyonunun kendisi tarafından zorunlu kılınmayan gizli varsayımlar veya “örüntüler” eklenmediğini güvence altına alır.
Ölçek Ayrımı (Sıcaklık Parametresi): Üstel fonksiyon, bir “sıcaklık” veya “ters sıcaklık” parametresi olan \(\beta = 1/T\)’nin tanıtılmasına olanak tanır. Bu, SMC’ye bir mekanik avantaj sağlar:
Düzleştirme ve Keskinleştirme: \(T\) yüksek olduğunda, dağılım neredeyse düzgündür ve parçacıkların tüm durum uzayını keşfetmesine olanak tanır. \(T \to 0\) iken, üstel fonksiyon değerler arasındaki farkları “gerer” ve olasılık kütlesinin küresel minimumlar üzerinde yığılmasına neden olur.
Oranların Ölçek Değişmezliği: İki durum arasındaki olasılık oranı yalnızca maliyetleri arasındaki farka bağlıdır:
\[\frac{P(x_1)}{P(x_2)} = \exp\left(-\frac{f(x_1) - f(x_2)}{T}\right)\]
Bu, örnekleyiciyi fonksiyonun mutlak büyüklüğü yerine göreli iyileştirmelere duyarlı kılar.
Matematiksel Kolaylık: Sıralı Monte Carlo’da, parçacıklarınızı güncellemek için önem ağırlıkları hesaplamanız gerekir. \(T_n\) sıcaklığındaki bir dağılımdan \(T_{n+1}\)’e geçerken, artımlı ağırlık şöyledir: \[w = \frac{\exp(-f(x)/T_{n+1})}{\exp(-f(x)/T_n)} = \exp\left(-f(x) \left( \frac{1}{T_{n+1}} - \frac{1}{T_n} \right) \right)\]
Logaritmik Doğrusallık: Üslerin özellikleri sayesinde, bu güncellemeler logaritmik uzayda toplamsal hale gelir. Bu, sayısal taşma/küçüme sorunlarını önler ve Etkin Örneklem Boyutu’nun (ESS) hesaplanmasını basitleştirir.
Türevi alınabilirlik: Üstel fonksiyon pürüzsüzdür ve sonsuz kez türevlenebilir.
Toplamsallık ve Bağımsız Değişkenler: Amaç fonksiyonunuz bağımsız bileşenlerin toplamıysa, \(f(x, y) = g(x) + h(y)\), üstel dönüşüm bu toplamı olasılıkların bir çarpımına dönüştürür: \(\exp(-(g(x) + h(y))) = \exp(-g(x)) \cdot \exp(-h(y))\). Bu, verimli yüksek boyutlu örneklemenin temel taşı olan ortak dağılımın çarpanlara ayrılmasına olanak tanır.
Örnek
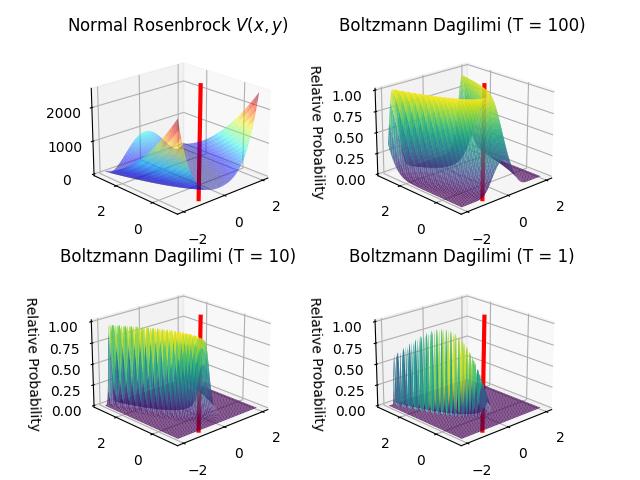
Çetin bir optimizasyon örneği bulalım, Rosenbrock fonksiyonu. Bu fonksiyonu \(\exp\) ile Boltzmann dağılımı haline döndürüyoruz, ve altta farklı \(T\)’ler le nasıl dağılım çeşitleri elde ettiğimizi görebiliyoruz.
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import cm
def Rosenbrock(x, y):
return (1 + x)**2 + 100*(y - x**2)**2
G = 250
x = np.linspace(-2, 2, G)
y = np.linspace(-1, 3, G)
X, Y = np.meshgrid(x, y)
Z_energy = Rosenbrock(X, Y)
temperatures = [100, 10, 1]
fig = plt.figure()
p_opt = [-1,1]
ax1 = fig.add_subplot(2, 2, 1, projection='3d')
ax1.plot_surface(X, Y, Z_energy, rstride=5, cstride=5, cmap='jet', alpha=0.5)
line_x = [p_opt[0], p_opt[1]]
line_y = [p_opt[0], p_opt[1]]
line_z = [0, np.max(Z_energy)] # From bottom to the top of the plot
ax1.plot(line_x, line_y, line_z, color='red', linewidth=3, label='Optimum (1,1)')
ax1.set_title("Normal Rosenbrock $V(x,y)$")
ax1.view_init(21, -133)
for i, T in enumerate(temperatures):
ax = fig.add_subplot(2, 2, i + 2, projection='3d')
Z_boltz = np.exp(-(Z_energy - np.min(Z_energy)) / T)
Z_boltz /= np.max(Z_boltz)
surf = ax.plot_surface(X, Y, Z_boltz, rstride=5, cstride=5, cmap='viridis', alpha=0.8, edgecolor='none')
line_x = [p_opt[0], p_opt[1]]
line_y = [p_opt[0], p_opt[1]]
line_z = [0, np.max(Z_boltz)]
ax.plot(line_x, line_y, line_z, color='red', linewidth=3, label='Optimum (1,1)')
ax.set_title(f"Boltzmann Dagilimi (T = {T})")
ax.set_zlabel("Relative Probability")
ax.view_init(21, -133)
plt.tight_layout()
plt.savefig('stat_230_opt_01.jpg')
Dikey kırmızı çizgi Rosenbrock’un bilinen minimum noktasını gösteriyor, (-1,1). \(P(x)\)’e gelirsek, matematiksel tanıma göre \(T\) yüksekken Boltzmann yoğunluğu \(P(x)\) kabaca \(f(x)\) gibidir, \(T \to 0\) iken (optimum noktası bağlamında) \(f(x)\)’e daha yaklaşır. Üstteki resimlerde \(T=100\) değerinde minimum nokta \(P(x)\)’in genel olarak maksimuma yakın olan bölgelerine işaret ediyor (eksi çarpımı ile fonksiyon ters döndüğü için minimum maksimum haline geldi).
Aynı mantığı takip edersek \(T=1\) grafiğinde net maksimal bir tepe görmeliyiz, fakat bunu göremiyoruz, sebebi grafiklemenin çözünürlüğü, yani maksimum orada ama çok detaylı bir çözünürlük ile gözüküyor. Alttaki kodda -1,1 etrafına odaklanırsak,
import numpy as np
import matplotlib.pyplot as plt
x_zoom = np.linspace(-1.1, -0.9, 250)
y_zoom = np.linspace(0.9, 1.1, 250)
X_z, Y_z = np.meshgrid(x_zoom, y_zoom)
Z_energy_z = Rosenbrock(X_z, Y_z)
T = 1
Z_boltz_z = np.exp(-(Z_energy_z - np.min(Z_energy_z)) / T)
Z_boltz_z /= np.max(Z_boltz_z) # Normalize peak to 1.0
fig, ax = plt.subplots(subplot_kw={'projection': '3d'}, figsize=(10, 8))
ax.plot_surface(X_z, Y_z, Z_boltz_z, rstride=5, cstride=5, cmap='viridis', alpha=0.8)
ax.plot([-1, -1], [1, 1], [0, 1], color='red', linewidth=4, label='Optimum (-1,1)')
ax.set_title(f"Zoomed Boltzmann Density (T = {T})")
ax.set_zlabel("Relative Probability")
ax.legend()
ax.view_init(21, -133)
plt.savefig('stat_230_opt_02.jpg')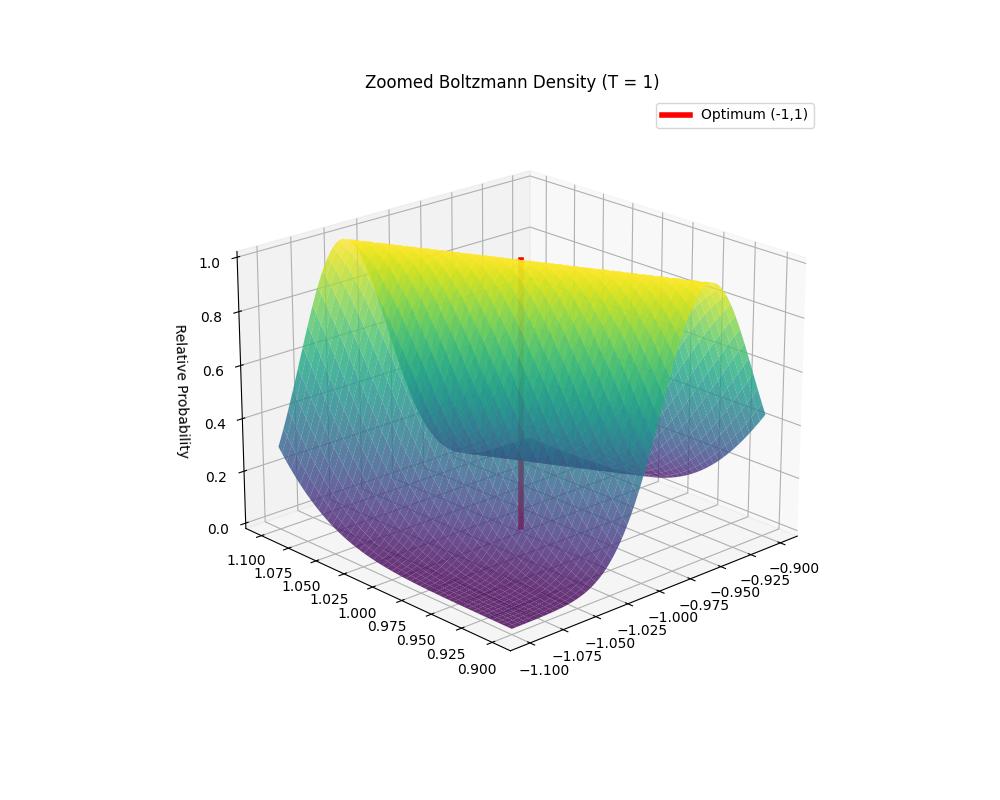
Orada bir tepe olduğunu görüyoruz.
Şimdi Rosenbrock’u dağılım haline çevirilmiş halini Metropolis (MCMC) yaklaşımı ile gezelim. O bir yoğunluk olduğuna göre onu her dağılımı gezebilen herhangi bir yaklaşım ile gezebilmeliyiz. İşin optimizasyon kısmını halledebilmek için de bu gezimi yaparken sürekli o ana kadar gördüğümüz en minimum değeri (ve ona tekabül eden kordinatları) akılda tutarız. Gezim bitince bu değerleri rapor ederiz.
Dikkat: minimumu akılda tutuyoruz, çünkü değerleri Rosenbrock fonksiyonunun kendisini çağırarak hesaplıyoruz. Simülasyonun bize sağladığı kabiliyet fonksiyonun önemli bölgelerini gezebilme kabiliyetidir.
from numpy.random import multivariate_normal as mvn
np.random.seed(0)
def Rosenbrock(x, y):
return (1 + x)**2 + 100*(y - x**2)**2
proposal_var = 0.005
burn_in = 100
n_iters = 5000
T_0 = 100
T_f = 0.01
T = T_0
gamma = (T_f / T_0) ** (1 / n_iters) # ~0.9988, computed automatically
curr = np.random.uniform(low=[-3, -3],high=[3, 10],size=2 )
min_p_coord = [0,0]
min_p_val = 1000
accepted_count = 0
for i in range(1, n_iters):
prop = curr + mvn(mean=np.zeros(2), cov=np.eye(2) * proposal_var)
energy_curr = Rosenbrock(*curr)
energy_prop = Rosenbrock(*prop)
alpha = min(1, np.exp((energy_curr - energy_prop) / T))
if np.random.uniform() < alpha:
curr = prop
accepted_count += 1
if i > burn_in:
if energy_curr < min_p_val:
min_p_coord = curr
min_p_val = energy_curr
T = T_0 * (gamma ** i)
print ('minimum nokta',min_p_coord)
print ('minimum deger',min_p_val)
acceptance_rate = accepted_count / n_iters
print(f"Kabul Orani: {acceptance_rate:.2%}")minimum nokta [-1.00635415 1.01207271]
minimum deger 8.606730178162036e-05
Kabul Orani: 48.62%Üstteki değerler hakikaten Rosenbrock’un bilinen minimum noktasına oldukca yakın.
Kod içindeki bir kısmı aydınlatalım, niye
min(1, np.exp((energy_curr - energy_prop) / T)) kullandık?
Çünkü bir Metropolis örnekleyici iki olasılık hesabının oranına göre
hareketi kabul eder, diyelim prop teklif, curr
o andaki durumu temsil ediyorsa,
\[ \alpha = \min\left(1, \frac{P(prop)}{P(curr)}\right) \]
Elimizdeki dağılım Boltzmann dağılımı olduğu için \(P(x) \propto \exp(-V(x)/T)\) formülü var, o zaman oran (bir bölüm işlemi) şu hale dönüşür,
\[ \frac{P(prop)}{P(curr)} = \frac{\exp(-V(prop)/T)}{\exp(-V(curr)/T)} = \exp\left(\frac{V(curr) - V(prop)}{T}\right) \]
Bu formül kodda görülen hesaptır.
Şimdi dağılımı bir parçacık filtresi ile gezelim. Aynı şekilde gezim sırasın minimum değerleri kayda geçiyoruz. Döngü içindeki ufak sarsma adımına dikkat, parçacık çeşitliliğini arttırmak için eklenmesi gerekiyor.
n_particles = 1000
n_steps = 100
n_mcmc_steps = 5
proposal_var = 0.005
T_start = 100.0
T_end = 1
particles = np.zeros((n_particles, 2))
particles[:, 0] = np.random.uniform(-3, 3, n_particles) # Initial X
particles[:, 1] = np.random.uniform(-3, 10, n_particles) # Initial Y
# dikkat linspace degil, geomspace, logaritmic azalma yapiliyor
temperatures = np.geomspace(T_start, T_end, n_steps)
min_val = float('inf')
min_coord = [0, 0]
for T_curr in temperatures:
energies = Rosenbrock(particles[:, 0], particles[:, 1])
step_min_idx = np.argmin(energies)
if energies[step_min_idx] < min_val:
min_val = energies[step_min_idx]
min_coord = particles[step_min_idx].copy()
unnorm_weights = np.exp(-(energies - np.min(energies)) / T_curr)
weights = unnorm_weights / np.sum(unnorm_weights)
indices = np.random.choice(np.arange(n_particles), size=n_particles, p=weights)
particles = particles[indices]
curr_energies = Rosenbrock(particles[:, 0], particles[:, 1])
# Ufak MCMC adimi, "sarsma"
for _ in range(n_mcmc_steps):
noise = np.random.normal(0, np.sqrt(proposal_var), size=(n_particles, 2))
prop = particles + noise
prop_energies = Rosenbrock(prop[:, 0], prop[:, 1])
diff = (curr_energies - prop_energies) / T_curr
alpha = np.exp(np.clip(diff, -100, 0))
accept = np.random.uniform(size=n_particles) < alpha
particles[accept] = prop[accept]
curr_energies[accept] = prop_energies[accept]
print(f"Final Best Coord: {min_coord}")
print(f"Final Best Value: {min_val}")Final Best Coord: [-1.00018448 1.00031523]
Final Best Value: 3.2312280609237785e-07Çok daha zor bir fonksiyon kullanalım, Genz Çarpım Tepe (Genz Product Peak) fonksiyonu [1],
\[f(x) = \prod_{i=1}^{D} \left[ a_i^{-2} + (x_i - w_i)^2 \right]^{-1}\]
Fonksiyonun 3 boyuttaki hali alttadır,
import numpy as np
import matplotlib.pyplot as plt
a = np.array([5.0, 5.0]) # sharpness: larger => narrower peak
w = np.array([0.5, 0.5]) # peak location
N = 300
x1 = np.linspace(0, 1, N)
x2 = np.linspace(0, 1, N)
X1, X2 = np.meshgrid(x1, x2)
def genz(x,y):
return 1.0 / ((1/a[0])**2 + (x - w[0])**2) / ((1/a[1])**2 + (y - w[1])**2)
Z = genz(X1,X2)
fig = plt.figure(figsize=(10, 7))
ax = fig.add_subplot(111, projection='3d')
surf = ax.plot_surface(X1, X2, Z, cmap='viridis', linewidth=0, antialiased=True, alpha=0.92)
ax.set_xlabel('$x_1$', fontsize=13, labelpad=8)
ax.set_ylabel('$x_2$', fontsize=13, labelpad=8)
ax.set_zlabel('$f(x_1, x_2)$', fontsize=13, labelpad=8)
ax.view_init(elev=30, azim=-60)
plt.tight_layout()
plt.savefig('stat_230_opt_03.jpg')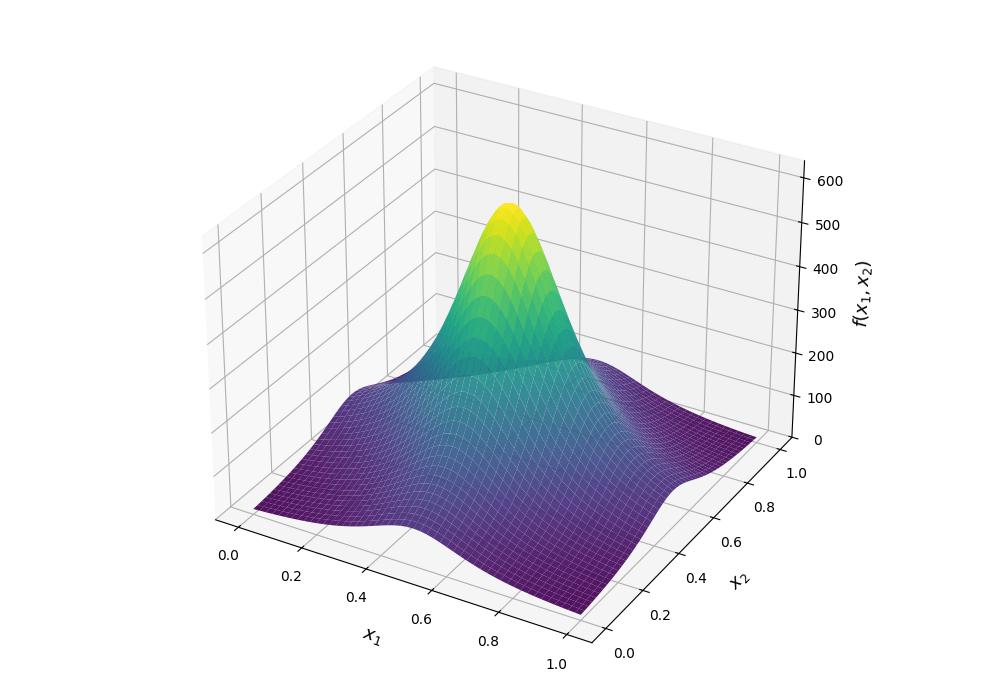
Genz fonksiyonu istenen boyutta tanımlanabilir, ve boyutlar arttıkça
minimum noktası çok daha zor bulunur hale gelir. Biz şimdi optimizasyonu
iyice zorlaştırmak için 100 boyutlu bir Genz fonksiyonu seçiyoruz. Onu
dağılım haline getireceğiz, fakat bu sefer dağılımı paralel parçacık
filtresi ile gezeceğiz… Parçacık filtrelerinin parallelliğe yatkın bir
yaklaşım olduğunu görmüştük, her parçacık farklı bir CPU/GPU çekirdeği
üzerinde işleyebilir. Alttaki pf_tf.py kodu da aynen bunu
yapıyor.
Paralel
Starting SMC for 100D Genz Product Peak with 1000000 particles...
Step 1 | Temp: 50.0000 | Best: 101.3879 | Accept: 99.72% | Time: 7.77s
Step 2 | Temp: 42.0224 | Best: 100.6690 | Accept: 99.65% | Time: 0.05s
Step 3 | Temp: 35.3176 | Best: 99.4449 | Accept: 99.57% | Time: 0.11s
Step 4 | Temp: 29.6826 | Best: 99.5849 | Accept: 99.45% | Time: 0.11s
Step 5 | Temp: 24.9467 | Best: 98.9302 | Accept: 99.30% | Time: 0.05s
Step 6 | Temp: 20.9664 | Best: 98.5596 | Accept: 99.09% | Time: 0.06s
Step 7 | Temp: 17.6212 | Best: 98.2959 | Accept: 98.83% | Time: 0.05s
Step 8 | Temp: 14.8097 | Best: 97.5658 | Accept: 98.46% | Time: 0.07s
Step 9 | Temp: 12.4468 | Best: 97.4290 | Accept: 97.95% | Time: 0.06s
Step 10 | Temp: 10.4609 | Best: 95.9413 | Accept: 97.25% | Time: 0.06s
Step 11 | Temp: 8.7918 | Best: 96.2469 | Accept: 96.34% | Time: 0.08s
Step 12 | Temp: 7.3891 | Best: 95.7737 | Accept: 95.14% | Time: 0.07s
Step 13 | Temp: 6.2101 | Best: 94.9233 | Accept: 93.63% | Time: 0.06s
Step 14 | Temp: 5.2193 | Best: 94.4495 | Accept: 91.87% | Time: 0.07s
Step 15 | Temp: 4.3865 | Best: 94.0814 | Accept: 89.74% | Time: 0.09s
Step 16 | Temp: 3.6867 | Best: 93.6314 | Accept: 87.29% | Time: 0.06s
Step 17 | Temp: 3.0984 | Best: 93.2184 | Accept: 84.43% | Time: 0.05s
Step 18 | Temp: 2.6041 | Best: 92.8988 | Accept: 81.02% | Time: 0.05s
Step 19 | Temp: 2.1886 | Best: 92.1003 | Accept: 77.09% | Time: 0.05s
Step 20 | Temp: 1.8394 | Best: 92.1704 | Accept: 72.68% | Time: 0.05s
Step 21 | Temp: 1.5459 | Best: 91.8560 | Accept: 67.76% | Time: 0.04s
Step 22 | Temp: 1.2993 | Best: 91.6460 | Accept: 62.38% | Time: 0.04s
Step 23 | Temp: 1.0920 | Best: 91.3448 | Accept: 56.76% | Time: 0.05s
Step 24 | Temp: 0.9177 | Best: 90.9284 | Accept: 50.88% | Time: 0.05s
Step 25 | Temp: 0.7713 | Best: 90.8716 | Accept: 44.95% | Time: 0.05s
Step 26 | Temp: 0.6482 | Best: 90.7874 | Accept: 39.08% | Time: 0.05s
Step 27 | Temp: 0.5448 | Best: 90.7200 | Accept: 33.46% | Time: 0.05s
Step 28 | Temp: 0.4579 | Best: 90.6329 | Accept: 28.18% | Time: 0.04s
Step 29 | Temp: 0.3848 | Best: 90.5655 | Accept: 23.24% | Time: 0.05s
Step 30 | Temp: 0.3234 | Best: 90.4675 | Accept: 18.87% | Time: 0.05s
Step 31 | Temp: 0.2718 | Best: 90.4270 | Accept: 15.07% | Time: 0.05s
Step 32 | Temp: 0.2285 | Best: 90.3473 | Accept: 11.85% | Time: 0.05s
Step 33 | Temp: 0.1920 | Best: 90.3473 | Accept: 9.21% | Time: 0.04s
Step 34 | Temp: 0.1614 | Best: 90.2679 | Accept: 7.04% | Time: 0.04s
Step 35 | Temp: 0.1356 | Best: 90.2034 | Accept: 5.35% | Time: 0.04s
Step 36 | Temp: 0.1140 | Best: 90.1353 | Accept: 3.99% | Time: 0.05s
Step 37 | Temp: 0.0958 | Best: 90.1353 | Accept: 2.95% | Time: 0.05s
Step 38 | Temp: 0.0805 | Best: 90.1199 | Accept: 2.14% | Time: 0.05s
Step 39 | Temp: 0.0677 | Best: 90.0747 | Accept: 1.49% | Time: 0.05s
Step 40 | Temp: 0.0569 | Best: 90.0467 | Accept: 0.94% | Time: 0.05s
Step 41 | Temp: 0.0478 | Best: 90.0419 | Accept: 0.64% | Time: 0.06s
Step 42 | Temp: 0.0402 | Best: 90.0410 | Accept: 0.45% | Time: 0.05s
Step 43 | Temp: 0.0338 | Best: 90.0092 | Accept: 0.32% | Time: 0.05s
Step 44 | Temp: 0.0284 | Best: 90.0085 | Accept: 0.24% | Time: 0.06s
Step 45 | Temp: 0.0238 | Best: 89.9678 | Accept: 0.17% | Time: 0.07s
Step 46 | Temp: 0.0200 | Best: 89.9678 | Accept: 0.13% | Time: 0.06s
Step 47 | Temp: 0.0168 | Best: 89.9493 | Accept: 0.09% | Time: 0.07s
Step 48 | Temp: 0.0142 | Best: 89.9168 | Accept: 0.09% | Time: 0.06s
Step 49 | Temp: 0.0119 | Best: 89.8920 | Accept: 0.08% | Time: 0.05s
Step 50 | Temp: 0.0100 | Best: 89.8833 | Accept: 0.05% | Time: 0.07s
==============================
Final Best Energy: 89.849319458008
Accuracy Check (Found vs Actual for first 5 dims):
Dim 0: Found 0.200349 | Actual 0.200000
Dim 1: Found 0.205520 | Actual 0.206061
Dim 2: Found 0.210462 | Actual 0.212121
Dim 3: Found 0.218188 | Actual 0.218182
Dim 4: Found 0.225209 | Actual 0.224242
==============================Kod tek GPU üzerinde (Google Colab’da denenebilir) birkaç saniye içinde sonucu buluyor. Üstte ilk 5 boyutta gerçek minimum noktasına ne kadar yaklaşıldığını göstermek için bulunan ve gerçek optimal nokta yanyana gösterilmiş, değerler oldukca yakın.
Genz fonksiyonu optimizasyonun en zor problemlerinden biridir. Fakat parallellik, ve olasılıksal yaklaşım ile yaklaşık optimal noktasını hızlı bir şekilde bulabiliyoruz.
Kodlar
Kaynaklar
[1] Genz, Testing multidimensional integration routines. In Proceeding of International Conference on Tools, Methods and Languages for Scientific and Engineering Computation, 81–94. Elsevier North-Holland, Inc., 1984.