Dünya Kupası 2014, Veri Analizi
Daha önceki maç verisine bakarak 2014 Dünya Kupası maçlarını tahmin
edebilen istatistik (yapay öğrenim) teknikleri Google mühendisleri
tarafından paylaşıldı, kullanılan teknik lojistik regresyon. Verinin
şekillendirilmesi, veriden özellik (feature) yaratmak işin püf
noktalarından - veri hangi detay seviyesinde (maç seviyesinde mi takım
seviyesinde mi) ve hangi kolonlar üzerinden modele dahil edilecek?
Görülüyor ki nihai regresyon her maç için iki takımı yanyana koyuyor
(A takımı öğeleri belli kolonlar B öğeleri belli kolonlar) ve 1,0
etiketini tahmine uğraşıyor. Öğelerin önemli bir özelliği o ana kadar
her iki takımın oynadığı önceki N maçın özeti olmaları. Yani A takımı
son 3 maçta (N=3) maçta dakikada 5 pas atmışsa passes öğesi 5
olacaktır, B takımı dakikada 10 atmışsa op_passes 10
olacaktır. Böylece lojistik regresyona 5'e karşı 10 pas ağırlığı olan
bir veri satırı hakkında irdeleme yapma imkanı veriyoruz; ve bilinen
etikete göre LR gerekli ağırlıkları hesaplayarak sonuca erişiyor.
Projede kullanılan 4 Python dosyası var:
match_stats: Maç istatistiklerini yükleyen kodlar.
features: Ham istatistik verileri özelliklere (features) döndürüyor,
ki bu özellikler yapay öğrenim modeline girilebilsin. Bu özellikler önceki
K maçın verilerini özetleme amaçlı yaratıldılar, ki bu özelliklere
dayanarak bir sonraki maçı tahmnin edebilelim.
world_cup: Veriyi temizlemek ve modeli kurmak için kullanılan
yardımcı kodlar.
power: Birbiriyle belli sayıda maç yapmış takımların bir ``güç
sıralamasını'' hesaplamak.
Özellik inşası
Sonraki maç tahmini için önceki K maçın özet istatistiklerine bakıyoruz, K'nın
ne olduğu history_size ile tanımlı.
import world_cup
import features
import match_stats
import pandas as pd
import math
pd.set_option('display.max_columns', None)
history_size = 3
game_summaries = features.get_game_summaries()
data = features.get_features(history_size)
Bu özellikler, dediğimiz gibi, önceki K maçın özeti. Bu özetlerin çoğu bir ortalamadır, ayrıca bu ortalamaların çoğu dakika bazlı çünkü maç zamanını aşan maçları da hesaba katmak için.. Eğer maç başına yapılan pas değeri alınsaydı, o zaman vakti aşan bir maçta o değer normalden çok daha fazla olacaktı, bu modeli bozardı.
Modelde kullanılacak özellikler:
is_home: Takım evinde mi, deplasmanda mı oynuyor. Futbolda bu
değişkenin çok önemli olduğunu biliyoruz.
avg_points: Önceki K maçta kazanılan ortalama puan (galibiyet için
3, eşitlik için 1, kayıp için 0).
avg_goals: Önceki K maçta atılan averaj gol.
op_average_goals: Rakip tarafından son K maçta atılan averaj gol.
pass_70/80: Hücum sahasının 30%-20%'sinde dakika başına verilen
başarılı pas.
op_pass70/80: Hücum sahasının 30%-20%'sinde rakip tarafından
verilmiş dakika bazında başarılı paslar.
expected_goals: Son K maçtaki gol beklentisi, ki bu beklenti atılan
şut ve ve şutun kaleden uzaklığı baz alınarak hesaplanan bir sayı.
passes: Dakika başına atılan paslar.
bad_passes: Dakika bazında verilen ama başarılı olmayan paslar.
pass_ratio: Başarılı pasların oranı.
corners: Dakika bazında atılan kornerler.
fouls: Yapılan faul sayısı (dk bazlı)
cards: Kırmızı ya da sarı alınan kart ceza sayısı (maç başına).
shots: Dakika bazında atılan şut.
op_*: Rakipler hakkındaki bazı tarihi istatistikler. Dikkat, bu
`rakip''opteamnamede gösterilen rakip değil, genel olarak bu
takımın rakiplerinin ona karşı nasıl oynadığını göstermeye çalışan bir
istatistik. Meselaop_corners` bu takımın rakiplerinin dakika başına
kaç korner kazandığını gösteriyor.
*_op_ratio: Takimin istatistiklerinin rakiplerine olan orani [?]
Ozellik olmayan kolonlar
matchid: Maçın id'si
teamid: Takımın id'si
op_teamid: Rakip takımın özgün id'si
team_name: Takımın ismi
op_team_name: Rakip takımın ismi
timestamp: Maç ne zaman oynandı
competitionid: Genel müsabakayı gösteren kod (dünya kupası, vs).
Hedef kolonlar:
Alttaki kolonlar tahmin edilmeye uğraşılabilecek olan kolonlar. Eğer bilinen veri üzerinde tahmin yapmak istiyorsak, bu kolonları tahmin öncesi dışarı atmalıyız, bunu unutmayalım. Birkaç hedef kolon var ama, biz sadece kazanılan puanı tahmin etmeye uğraşacağız, belki diğer modeller diğer kolonları tahmin etmeye uğraşırlar, mesela atılan gol sayısı gibi.
points: Maçın puan sonucu.
goals: teamid deki takımın attığı gol sayısı.
op_goals: op_teamid ile gösterilen takımın attığı gol sayısı.
club_data = data[data['competitionid'] != 4]
# Show the features latest game in competition id 4, which is the world cup.
print (data[data['competitionid'] == 4].iloc[0])
matchid 731828
teamid 366
op_teamid 632
competitionid 4
seasonid 2013
is_home 0
team_name Netherlands
op_team_name Argentina
timestamp 2014-07-09 21:00:00.000000
goals 0
op_goals 0
points 1
avg_points 2.333333
avg_goals 1.333333
op_avg_goals 0.333333
pass_70 0.472036
pass_80 0.150698
op_pass_70 0.26478
op_pass_80 0.078501
expected_goals 1.444374
op_expected_goals 0.411425
passes 3.834864
bad_passes 1.013622
pass_ratio 0.765595
corners 0.070991
fouls 0.126237
cards 1.0
shots 0.155226
op_passes 3.38986
op_bad_passes 1.024551
op_corners 0.03468
op_fouls 0.157066
op_cards 2.666667
op_shots 0.092497
goals_op_ratio 1.333333
shots_op_ratio 1.702273
pass_op_ratio 1.025426
Name: 0, dtype: object
Maç bazında atılan goller ve maçın sonucunu eksenlere alarak bir tablo yaratalım (crosstab).
import pandas as pd
print (pd.crosstab(
club_data['goals'],
club_data.replace(
{'points': {
0: 'lose', 1: 'tie', 3: 'win'}})['points']))
points lose tie win
goals
0 768 279 0
1 508 416 334
2 134 218 531
3 23 42 325
4 2 6 158
5 0 2 67
6 0 0 13
7 0 0 6
8 0 0 1
5'den fazla gol atmak tabii ki kazanmayı garantiliyor, hiç atmamak 75\% ihtimalle kaybedilecek demektir (bazen de beraberlik olur tabii!). Not: Fakat tabloda 4 gol sonrası kazanımlar direk artmıyor, niye? Çünkü bu maçlar uzatma sonrası atılan penaltılardan geliyor, her iki takımda bu sırada çok gol atıyor, ve biri mutlaka kaybediyor [1].
Modeli eğitmek
Veri tabanımızdaki klüp verisini kullanarak (yani hiç dünya kupası verisi
kullanmadan) eğiteceğiz. Bu kod world_cup.py içinde. Sonuç bir
lojistik regresyon modeli olacak, ve sonra test verisi üzerinde tahmin
yapacağız. Regresyonun Rsquared değerini göstereceğiz, ki bu eğitim
verisi üzerinden gösterilebilir. Rsquared modelin veriye ne kadar uyduğunu
gösteren bir rakamdır, ne kadar yüksekse o kadar iyidir.
import world_cup
import match_stats
pd.set_option('display.width', 80)
# Don't train on games that ended in a draw, since they have less signal.
train = club_data.loc[club_data['points'] != 1]
# train = club_data
(model, test) = world_cup.train_model(
train, match_stats.get_non_feature_columns())
print ("Rsquared: %0.03g" % model.prsquared)
Rsquared: 0.149
Önemli özellikleri seçmek
Lojistik regresyon modelimiz regülarizasyon kullanıyor; bu demektir ki daha çetrefil modeller cezalandırılıyor. Bu cezalandırmanın yan etkisi olarak biz hangi özelliklerin daha önemli olduğunu görebiliyoruz, çünkü daha önemsiz olan özellikler modelden atılıyorlar (katsayıları sıfıra iniyor).
Bu bağlamda özellikleri üçe ayırabiliriz:
Pozitif özellikler: Bu özellikler mevcut ise takımın kazanma şansı yükseliyor.
Negative özellikler: Tam tersi
Atılan değerler: Önemli olmayan özellikler, ki bu özellikler modele dahil edilirse aşırı uygunluk (overfitting) durumu ortaya çıkar.
def print_params(model, limit=None):
params = model.params.copy()
params.sort_values(ascending=False)
del params['intercept']
if not limit:
limit = len(params)
print("Pozitif ozellikler")
params.sort_values(ascending=False)
print (np.exp(params[[param > 0.001 for param in params]]).sub(1)[:limit])
print("\nAtilan ozellikler")
print (params[[param == 0.0 for param in params]][:limit])
print("\nNegatif ozellikler")
params.sort_values(ascending=True)
print (np.exp(params[[param < -0.001 for param in params]]).sub(1)[:limit])
print_params(model, 10)
Pozitif ozellikler
is_home 0.848337
avg_goals 0.092000
pass_70 0.254729
expected_goals 0.169235
passes 0.051791
fouls 0.062809
shots 0.001786
op_passes 0.120319
pass_op_ratio 0.018882
opp_pass_80 0.014662
dtype: float64
Atilan ozellikler
avg_points 0.0
op_avg_goals 0.0
op_pass_70 0.0
pass_ratio 0.0
corners 0.0
op_bad_passes 0.0
op_fouls 0.0
op_cards 0.0
goals_op_ratio 0.0
shots_op_ratio 0.0
dtype: float64
Negatif ozellikler
pass_80 -0.014450
op_pass_80 -0.087566
op_expected_goals -0.042092
bad_passes -0.070335
cards -0.064461
op_corners -0.137309
op_shots -0.017699
opp_avg_goals -0.084249
opp_pass_70 -0.203015
opp_expected_goals -0.144740
dtype: float64
Klüp verisi üzerinde tahmin
predicted: Takımın kazanma şansı (tahmin).
points: Gerçekten ne oldu.
results = world_cup.predict_model(model, test, match_stats.get_non_feature_columns())
predictions = world_cup.extract_predictions(results.copy(), results['predicted'])
print ('Dogru tahminler:')
print (predictions[(predictions['predicted'] > 50) & (predictions['points'] == 3)][:5])
Dogru tahminler:
team_name op_team_name predicted expected \
8 Portland Timbers Real Salt Lake 52.418756 Portland Timbers
42 Rayo Vallecano Granada CF 60.862465 Rayo Vallecano
49 Atlético de Madrid Getafe 64.383541 Atlético de Madrid
57 Colorado Rapids Vancouver Whitecaps 51.836366 Colorado Rapids
58 Real Madrid Real Sociedad 64.100904 Real Madrid
winner points
8 Portland Timbers 3
42 Rayo Vallecano 3
49 Atlético de Madrid 3
57 Colorado Rapids 3
58 Real Madrid 3
print ('Yanlis tahminler:')
print (predictions[(predictions['predicted'] > 50) & (predictions['points'] < 3)][:5])
Yanlis tahminler:
team_name op_team_name predicted \
1 Seattle Sounders FC Vancouver Whitecaps 51.544963
2 New England Revolution Real Salt Lake 63.950714
3 Philadelphia Union FC Dallas 54.213693
14 New England Revolution Montreal Impact 52.762065
20 New York Red Bulls Toronto FC 55.533969
expected winner points
1 Seattle Sounders FC Vancouver Whitecaps 0
2 New England Revolution Real Salt Lake 0
3 Philadelphia Union FC Dallas 0
14 New England Revolution Montreal Impact 0
20 New York Red Bulls Toronto FC 0
Tahminlerimizi kontrol etmek
Kontrol için mesela hesabımızın rasgele tahminden ne kadar iyi olduğunu hesaplayabiliriz (lift) ya da AUC hesabı yapıp ROC eğrisini hesaplarız. AUC herhalde en iyisi, bu hesap çok ilginçtir, 0.5 (kafadan atmak) ve 1.0 arasındadır (mükemmel tahmin), ve bu hesap dengesiz veri setlerine karşı dayanıklıdır. Mesela 0/1 etiketi tahmininde test setinde diyelim ki yüzde 90 oranında olsa ve modelimiz sürekli 1 tahmin etse, basit bir ölçüm bize modelimizin yüzde 90 başarılı olduğunu söylerdi. AUC böyle durumlara karşı dayanıklıdır, bize 0.5 sonucunu verir.
baseline = (sum([yval == 3 for yval in club_data['points']])
* 1.0 / len(club_data))
y = [yval == 3 for yval in test['points']]
world_cup.validate(3, y, results['predicted'], baseline,
compute_auc=True)
plt.savefig('stat_worldcup_01.png')
(3) Lift: 1.42 Auc: 0.738
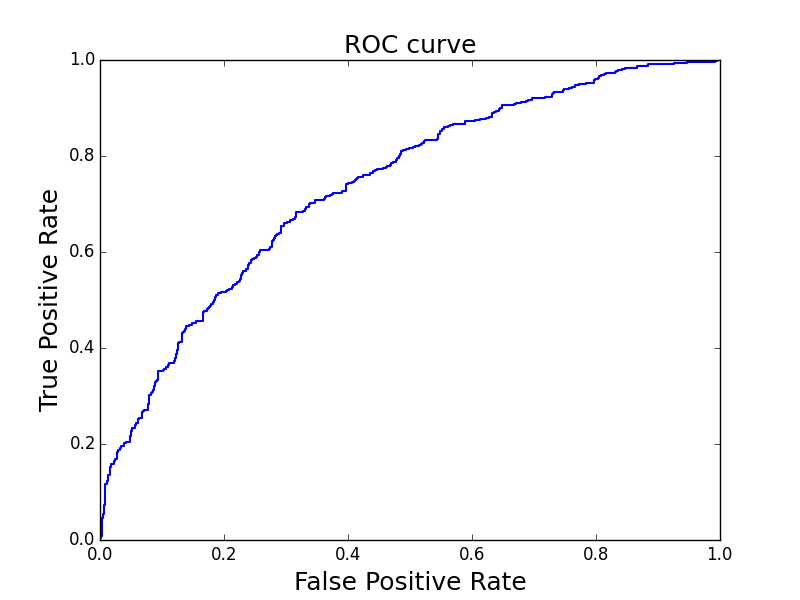
Modelde eksik olan bir şey var; sonraki maçı önceki birkaç maçın özetinden tahmin etmeye uğraşıyoruz ama belki bazı takımlar önceki K maçta çok zorlu rakiplerle uğraşmıştır, bazıları çok kolay rakiplerle uğraşmıştır. Bu durumda önceki maçların istatistiği bize tüm hikayeyi anlatmayacaktır.
Bu problemi çözmek için ayrı bir regresyon daha işletebiliriz. Bu regresyon bir güç sıralaması (power ranking) hesaplayabilir, bu hesap FIFA/CocaCola'nın enternasyonel takımlar için yaptığı güç sıralama hesabına benzer. ABD'de beyzbol ve Amerikan futbolu için de benzer bir hesap yapılıyor.
Güç sıralaması hesabını yaptıktan sonra -tek bir sayı, bazı takımlar için daha yüksek bazı takımlar için daha alçak, ki onun üzerinden sıralama yapılabilsin- onu bir özellik olarak lojistik regresyon modeline dahil edebiliriz. Güç sıralaması esas olarak şu tür irdelemelerin modelimize dahilini mümkün kılar; A takımı B'yi yendiyse, B C'yi yendiyse, A büyük ihtimalle C'yi yener. Bu tür bilgi niye önemli? Çünkü elimizde yapılabilecek tüm maçların kombinasyonu yok, maç verisi seyrek (sparse). Ama eldeki birkaç maçtan bir güç sıralaması hesaplayabilirsek, bu bize takımlar arasında, daha önce maç oynamamış olsalar bile, otomatik olarak bir ek irdeleme yapabilmemizi sağlayacaktır.
Sıralama hesabı yapıldıktan sonra bazı kontrolleri hızla, çıplak gözle yapabiliriz, mesela sonuca bakarız, eğer Wiggan (zayıf bir takım) 1.0 değeri almış, Chelsea (güçlü bir takım) 0.0 değeri almış ise bir şeyler yanlış demektir.
Tabii buna rağmen bazı takımlara hala uygun sıralama veremeyebiliriz, mesela A,B'yi, B,C'yi yeniyor, sonra veriye göre, C A'yı yeniyor. Bu şekilde sıralayamadığımız durumda takıma 0.5 verip tam ortaya koyacağız.
Ayrıca enternasyonel takımların sıralaması çok gürültülü veri olduğu ve (klüp verisinden bile daha) seyrek olduğu için onu yüzdeliklere (quartiles) ayırarak göstereceğiz, yani sıralamalar 0, .33, .66, or 1.0 olarak gözükecekler.
Fakat hesap işi bitince, ve bu sıralamayı nihai lojistik modele dahil edince başarı oranımızın zıplama yaptığını göreceğiz.
import power
def points_to_sgn(p):
if p > 0.1: return 1.0
elif p < -0.1: return -1.0
else: return 0.0
power_cols = [
('points', points_to_sgn, 'points'),
]
power_data = power.add_power(club_data, game_summaries, power_cols)
power_train = power_data.loc[power_data['points'] != 1]
# power_train = power_data
(power_model, power_test) = world_cup.train_model(
power_train, match_stats.get_non_feature_columns())
print ("\nRsquared: %0.03g, Power Coef %0.03g" % (
power_model.prsquared,
math.exp(power_model.params['power_points'])))
power_results = world_cup.predict_model(power_model, power_test,
match_stats.get_non_feature_columns())
power_y = [yval == 3 for yval in power_test['points']]
world_cup.validate(3, power_y, power_results['predicted'], baseline,
compute_auc=True, quiet=False)
print_params(power_model, 8)
plt.plot([0, 1], [0, 1], '--', color=(0.6, 0.6, 0.6), label='Luck')
# Add the old model to the graph
world_cup.validate('old', y, results['predicted'], baseline,
compute_auc=True, quiet=True)
plt.legend(loc="lower right")
plt.savefig('world_cup_02.png')
New season 2014
New season 2013
New season 2013
New season 2012
New season 2012
New season 2011
['D.C. United: 0.000', 'Real Zaragoza: 0.000', 'Blackburn Rovers:
0.000', 'Toronto FC: 0.015', 'Deportivo de La Coruña: 0.019',
'Reading: 0.019', 'Mallorca: 0.022', 'Wolverhampton Wanderers: 0.027',
'Almería: 0.034', 'Osasuna: 0.044', 'Bolton Wanderers: 0.045',
'Granada CF: 0.047', 'Queens Park Rangers: 0.049', 'Chivas USA:
0.050', 'Espanyol: 0.050', 'Aston Villa: 0.057', 'Real Betis: 0.062',
'Norwich City: 0.068', 'Getafe: 0.070', 'Rayo Vallecano: 0.074',
'Levante: 0.082', 'Real Valladolid: 0.084', 'Celta de Vigo: 0.090',
'Southampton: 0.117', 'Swansea City: 0.119', 'Sunderland: 0.119',
'Stoke City: 0.126', 'Fulham: 0.144', 'West Bromwich Albion: 0.148',
'Málaga: 0.151', 'Villarreal: 0.157', 'Athletic Club: 0.159',
'Valencia CF: 0.166', 'Valencia: 0.166', 'Sevilla: 0.176', 'West Ham
United: 0.183', 'Columbus Crew: 0.195', 'Real Sociedad: 0.264',
'Liverpool: 0.298', 'Everton: 0.316', 'Newcastle United: 0.322',
'Arsenal: 0.332', 'Montreal Impact: 0.370', 'Chelsea: 0.399', 'Chicago
Fire: 0.418', 'New England Revolution: 0.436', 'San Jose Earthquakes:
0.470', 'Atlético de Madrid: 0.473', 'Tottenham Hotspur: 0.496',
'Elche: 0.500', 'Wigan Athletic: 0.500', 'New York Red Bulls: 0.587',
'Philadelphia Union: 0.602', 'Houston Dynamo: 0.614', 'Sporting Kansas
City: 0.672', 'FC Dallas: 0.712', 'Real Madrid: 0.744', 'Vancouver
Whitecaps: 0.768', 'Real Salt Lake: 0.775', 'LA Galaxy: 0.803',
'Portland Timbers: 0.810', 'Seattle Sounders FC: 0.813', 'Manchester
City: 0.854', 'Colorado Rapids: 1.000', 'Barcelona: 1.000',
'Manchester United: 1.000']
Rsquared: 0.215, Power Coef 1.88
(3) Lift: 1.46 Auc: 0.75
Base: 0.374 Acc: 0.671 P(1|t): 0.728 P(0|f): 0.637
Fp/Fn/Tp/Tn p/n/c: 110/245/295/430 540/540/1080
Pozitif ozellikler
is_home 0.985326
pass_70 0.086559
pass_80 0.085011
expected_goals 0.035091
passes 0.045325
fouls 0.074550
op_passes 0.123758
op_bad_passes 0.006521
dtype: float64
Atilan ozellikler
avg_points 0.0
avg_goals 0.0
op_pass_70 0.0
bad_passes 0.0
pass_ratio 0.0
corners 0.0
cards 0.0
shots 0.0
dtype: float64
Negatif ozellikler
op_avg_goals -0.008003
op_pass_80 -0.024318
op_expected_goals -0.062309
op_corners -0.040983
opp_pass_70 -0.079663
opp_pass_80 -0.078350
opp_expected_goals -0.033901
opp_passes -0.043359
dtype: float64
(old) Lift: 1.42 Auc: 0.738
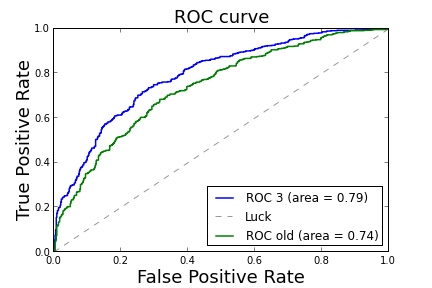
Şimdi dünya kupasını tahmin edelim!
Aynen klüp verisinde yaptığımız gibi dünya kupası için de benzer istatistikleri hesaplayabiliriz. Bu durumda elimizde hedefler olmayacak, yani kimin kazandığını bilemeyeceğiz (aslında bazı dünya kupası maçlarının sonucunu biliyoruz, ama tahminlerimizi hiçbir maçı bilmiyormuş gibi yapalım). Ve tekrar vurgulayalım: klüp verisiyle eğittiğimiz modeli kullanarak dünya kupasını tahmin edeceğiz. Yani model ve tahmin tamamen farklı takımlar üzerinden yapılacak!
features.get_wc_features() bize tüm dünya kupası maçları için
gereken özellikleri yaratıp döndürecektir.
import world_cup
import features
wc_data = world_cup.prepare_data(features.get_wc_features(history_size))
wc_labeled = world_cup.prepare_data(features.get_features(history_size))
wc_labeled = wc_labeled[wc_labeled['competitionid'] == 4]
wc_power_train = game_summaries[game_summaries['competitionid'] == 4].copy()
Ev sahası avantajı
Klüp verisi ile dünya kupası verisi arasındaki bazı farklardan biri budur: dünya kupasında bir maçta ev sahibi olmak ya da deplasmanda olmak ne demektir? Resmi olarak tek ev sahibi tüm 2014 kupasına ev sahipliği yapan Brezilya'dır, o zaman sadece Brezilya mı oynadığı maçlarda ev sahibi olabilir? Bu pek akla yatkın gelmiyor.
Belki diğer Latin Amerika takımlarını da ev sahibi olarak
görebiliriz.. Adam aynı kıtadan, belki o kıtaya alışık, iklimi vs ona
normal geliyor.. ? Olabilir mi? Diğer bazı modeller is_home u sadece
Brezilya'ya vermiş, sonra aynı kitadaki diğer takımlara da 'azıcık' ev
sahipliği vermişler, çünkü istatistiklere göre bu takımlar kendi
kıtalarında daha iyi performans gösteriyorlarmış, vs.
Biz daha değişik bir model kullanacağız, bu model belki biraz
sübjektif.. Biz is_home öğesine 0.0 ila 1.0 arasında bir değer
atayacağız, ve bu değerin büyüklüğü o takımın taraftarlarının hem sayı, hem
de destek enerjisi üzerinden ölçülecek. Bunu yapmamızın sebebi ilk turlarda
görüldüğü üzere, taraftarının daha iyi desteklediği takımların diğerlerine
göre daha iyi performans göstermesi. Mesela Şili'nin taraftarı takımını
müthiş destekledi, İspanya taraftarı oralı bile olmadı, Şili-İspanya maçını
Şili 2-0 kazandı. Bunun gibi pek çok maç gözlemledik, çoğunda güney Amerika
takımları vardı, ama çok taraftar gönderen takımlar da vardı, mesela
Meksika. Ya da ABD vardı, çok taraftarı vardı ama sessizdiler, onlar daha
düşük skorlar aldılar.
import pandas as pd
wc_home = pd.read_csv('wc_home.csv')
def add_home_override(df, home_map):
for ii in range(len(df)):
team = df.iloc[ii]['teamid']
if team in home_map:
df['is_home'].iloc[ii] = home_map[team]
else:
# If we don't know, assume not at home.
df['is_home'].iloc[ii] = 0.0
home_override = {}
for ii in range(len(wc_home)):
row = wc_home.iloc[ii]
home_override[row['teamid']] = row['is_home']
# Add home team overrides.
add_home_override(wc_data, home_override)
Dünya Kupası Güç Sıralaması
Bu hesabın dünya kupası verisi üzerinde yapılması lazım, çünkü güç sıralaması o takımların arasındaki maçlara dayanılarak yapılan bir hesap. Bu maçlar ise, dünya kupası takımları bağlamında, oldukça seyrek çünkü bazı takımlar bazı takımlarla neredeyse onyıldır oynamamış. Çoğu Avrupa takımı mesela güney Amerika takımıyla oynamamış, Asyalı takımlarla daha bile az oynamış. Klüp bazında kullandığımız aynı numarayı burada da kullanabiliriz, ama başarısızlığa hazır olmak lazım!
Hesap altta
# Guc verisiyle egitirken, kupa birden fazla maca yayildigi icin
# is_home'u 0.5'e set et. Yoksa 2010'daki kupa maclarina baktigimizda
# Guney Afrika yerine Brezilya'nin hala ev sahibi olduugnu zannedebilirdik.
wc_power_train['is_home'] = 0.5
wc_power_data = power.add_power(wc_data, wc_power_train, power_cols)
wc_results = world_cup.predict_model(power_model, wc_power_data,
match_stats.get_non_feature_columns())
New season 2013
New season 2009
New season 6
['Cameroon: 0.000', 'Honduras: 0.024', 'Nigeria: 0.047', 'Serbia:
0.072', 'USA: 0.073', 'Sweden: 0.098', 'Iran: 0.099', 'Algeria:
0.104', 'Japan: 0.115', 'Mexico: 0.127', 'Costa Rica: 0.130', "Côte
d'Ivoire: 0.148", 'Ecuador: 0.156', 'Chile: 0.166', 'England: 0.169',
'Australia: 0.177', 'Ukraine: 0.201', 'South Korea: 0.213',
'Switzerland: 0.240', 'France: 0.251', 'Uruguay: 0.318', 'Portugal:
0.382', 'Belgium: 0.466', 'Brazil: 0.470', 'Argentina: 0.486', 'Italy:
0.491', 'Greece: 0.500', 'Ghana: 0.500', 'Croatia: 0.500', 'Paraguay:
0.500', 'Slovakia: 0.500', 'Spain: 0.685', 'Germany: 0.740',
'Netherlands: 0.812', 'Colombia: 1.000']
Güç sırası da ayrı bir lojistik regresyon aslında, power.py içinde
biz bu regresyona giren matris ve etiketleri hesap yapılmadan önce çekip
çıkarttık, ve bir dosyaya kaydettirdik. Bakarsak,
games = pd.read_csv('/tmp/games.csv')
outcomes = pd.read_csv('/tmp/outcomes.csv')
Herhangi bir satıra göz atalım,
print ('mac', games[100:101])
print ('sonuc', outcomes[100:101])
mac 366 632 614 357 838 360 832 368 596 497 1215 1216 517 659 \
100 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
837 831 1041 536 359 1219 830 847 1042 537 1221 1266 119 \
100 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
114 494 535 118 575 835 507 1801 369 1804 364 365 522 \
100 0.0 1.5625 0.0 0.0 0.0 0.0 0.0 0.0 -1.5625 0.0 0.0 0.0 0.0
1161 510 361 1264 1223 511 1794 367 1224
100 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
sonuc 0
100 -1.0
Yani güç sıralaması lojistik regresyonuna girdi olan matrisin her satırı ayrı bir maç, her kolonu ise ayrı bir takım. Maç yapan iki takımın değerleri olacak, diğerleri sıfır olacak. Üstteki satır mesela, 369. takım ve rakipte 494. takım için,
raw_games = pd.read_csv('results-20140714-124014.csv')
tmp = raw_games[(raw_games['teamid'] == 369) & (raw_games['op_teamid'] == 494)]
tmp = tmp[['teamid','team_name','op_team_name','is_home','points']]
print (tmp)
teamid team_name op_team_name is_home points
4231 369 Denmark Cameroon 0 3
Danimarka Kamerun maçına aitmiş. Bu maçta Danimarka kazandı, ev sahibi Kamerun. Şimdi burada birkaç önemli takla atılıyor, Google veri bilimcileri lojistik regresyonda, girdi olarak, deplasman takımına her maç başında otomatik olarak eksi bir değer veriyorlar, ev sahibine artı değer veriyorlar. Etiket ise 'ev sahibi kazandı mı?' sorusunun cevabı.
Ev sahibi olup kazanmak daha kolay, regresyon bağlamında artı değere sahip olursanız, az bir katsayı modeli uydurmaya yeterli olabilir, pozitife hemen yaklaşırız. Diğer yandan deplasman takımı ne kadar iyi oynarsa, onun büyüyen katsayısı eksi değerini o kadar arttırır, ve ev sahibinin artışını (onun öğesi çarpı katsayısı yani) eksilterek kaybetme durumuna yaklaştırır.
Kötü oynayan deplasman takımının eksi değeri eksi katsayı ile çarpılır, ve daha büyük bir artı sayıyı oluşturur, ev sahibinin kazanması durumunu güçlendirir.
Katsayıları doğal olarak bir takımın ne kadar iyi olduğunu gösterecektir.
Tabii regresyona pek çok satır verilecek, Kamerun birden fazla satırda ortaya çıkabilecek (ama hep aynı kolonda, işin püf noktası burada), bazen artı değerli olarak (ev sahibi) bazen eksi değerli olarak (deplasman).
İtiraf etmek gerekir ki veri bilimi bağlamında üstteki teknik, model, düşünce tarzı dahiyane bir yaklaşım, alanın ruhunu göstermesi bakımından eğitici. Veri temsilinden tutun, regresyonun kodlanmasında çeyrekliklere ayırmak, az veri olduğu için yaklaşıksallık (convergence) olmayabilir diye değişik parametrelerle regresyonu birkaç kez işletmek, bunu yaklaşıksallık olana kadar yapmak, tam anlamıyla bir ders niteliği taşıyor.
Tahmin
Nihayet hazırlandığımız ana geldik. Şimdi dünya kupası maçlarını tahmin edelim. Birkaç kolon göstereceğiz:
predicted: Yüzde kaç ihtimalle (ismi ilk gelen) takımın kazanacağı
points: Gerçekten ne olduğu. Oynanmayan maç NaN. Dikkat,
penaltı atışlarına giden maçlar eşitlik olarak gösterilecek.
Ama bir dakika! Bu sonuçlar daha önce gösterdiğiniz [Google tahminleri kastediliyor] tahminlerinden değişik! Bunun sebepleri şunlar: Bazı hataları tamir ettik, yani kod değişti. İlk model mesela uzayan maçlar yüzünden kabaran istatistiklerin durumunu hesaba almıyordu.
İkinci sebep, model baştan planlı (deterministik) değil, eğitim verisi için verinin belli bir kısmını rasgele olarak seçiyoruz, bu sebeple sonuçlar bir hesaptan diğerine değişik çıkabiliyor (ki bazen sonuçlar çok değişik olabiliyor). Not: Aslında bu kod değiştirilerek rasgelelik içinden tamamen çıkartılabilir (ev ödeviniz!).
16'ıncı turu tahmin ederken mesela önceki 3 maçı, çeyrek finaller için
önceki 4, yarıfınaller için 5, ve finaller için önceki 6 maçı
kullandık [biz bu dokümanda önceki 3 maçı kullandık, history_size
parametresiyle oynayarak değişik sonuçlar kontrol edilebilir].
pd.set_option('display.max_rows', 5000)
pd.set_option('display.max_columns', 500)
pd.set_option('display.width', 1000)
wc_with_points = wc_power_data.copy()
wc_with_points.index = pd.Index(
zip(wc_with_points['matchid'], wc_with_points['teamid']))
wc_labeled.index = pd.Index(
zip(wc_labeled['matchid'], wc_labeled['teamid']))
wc_with_points['points'] = wc_labeled['points']
wc_pred = world_cup.extract_predictions(wc_with_points,
wc_results['predicted'])
# Reverse our predictions to show the most recent first.
wc_pred.reindex(index=wc_pred.index[::-1])
# Show our predictions for the games that have already happenned.
print (wc_pred)
team_name op_team_name predicted expected winner points
0 Argentina Germany 44.097950 Germany NA NaN
1 Netherlands Brazil 52.711308 Netherlands NA NaN
2 Netherlands Argentina 55.089671 Netherlands draw 1.0
3 Germany Brazil 52.791680 Germany Germany 3.0
4 Costa Rica Netherlands 17.418232 Netherlands draw 1.0
5 Belgium Argentina 29.081041 Argentina Argentina 0.0
6 Colombia Brazil 54.574633 Colombia Brazil 0.0
7 Germany France 81.681317 Germany Germany 3.0
8 USA Belgium 30.412694 Belgium Belgium 0.0
9 Switzerland Argentina 23.703298 Argentina Argentina 0.0
10 Algeria Germany 5.044527 Germany Germany 0.0
11 Nigeria France 10.745266 France France 0.0
12 Greece Costa Rica 57.996999 Greece draw 1.0
13 Mexico Netherlands 15.457466 Netherlands Netherlands 0.0
14 Uruguay Colombia 21.643826 Colombia Colombia 0.0
15 Chile Brazil 33.248079 Brazil draw 1.0
16 Germany USA 85.693707 Germany Germany 3.0
17 Ghana Portugal 63.890478 Ghana Portugal 0.0
18 Switzerland Honduras 67.070892 Switzerland Switzerland 3.0
19 France Ecuador 70.147018 France draw 1.0
20 Argentina Nigeria 89.621653 Argentina Argentina 3.0
21 Côte d'Ivoire Greece 36.873530 Greece Greece 0.0
22 Uruguay Italy 44.068286 Italy Uruguay 3.0
23 England Costa Rica 50.811389 England draw 1.0
24 Brazil Cameroon 91.057925 Brazil Brazil 3.0
25 Mexico Croatia 34.390212 Croatia Mexico 3.0
26 Spain Australia 86.025932 Spain Spain 3.0
27 Chile Netherlands 28.282544 Netherlands Netherlands 0.0
28 Portugal USA 52.652170 Portugal draw 1.0
29 Algeria South Korea 26.317364 South Korea Algeria 3.0
30 Ghana Germany 24.399186 Germany draw 1.0
31 Iran Argentina 12.232761 Argentina Argentina 0.0
32 Ecuador Honduras 54.617619 Ecuador Ecuador 3.0
33 France Switzerland 56.941174 France France 3.0
34 Costa Rica Italy 33.018788 Italy Costa Rica 3.0
35 Greece Japan 79.512996 Greece draw 1.0
36 England Uruguay 48.133873 Uruguay Uruguay 0.0
37 Croatia Cameroon 75.721526 Croatia Croatia 3.0
38 Chile Spain 33.871803 Spain Chile 3.0
39 Netherlands Australia 88.036065 Netherlands Netherlands 3.0
40 Mexico Brazil 25.555167 Brazil draw 1.0
41 USA Ghana 37.708800 Ghana USA 3.0
42 Nigeria Iran 30.426153 Iran draw 1.0
43 Portugal Germany 18.933847 Germany Germany 0.0
44 Honduras France 35.414093 France France 0.0
45 Ecuador Switzerland 49.518118 Switzerland Switzerland 0.0
46 Japan Côte d'Ivoire 32.050843 Côte d'Ivoire Côte d'Ivoire 0.0
47 Italy England 68.182745 Italy Italy 3.0
48 Costa Rica Uruguay 41.624123 Uruguay Costa Rica 3.0
49 Australia Chile 28.013709 Chile Chile 0.0
50 Netherlands Spain 45.491918 Spain Netherlands 3.0
51 Cameroon Mexico 36.828052 Mexico Mexico 0.0
52 Croatia Brazil 26.510888 Brazil Brazil 0.0
53 Spain Netherlands 53.126882 Spain Spain 3.0
54 Germany Uruguay 69.230393 Germany Germany 3.0
55 Spain Germany 49.094405 Germany Spain 3.0
56 Netherlands Uruguay 71.470148 Netherlands Netherlands 3.0
57 Spain Paraguay 78.167146 Spain Spain 3.0
58 Germany Argentina 41.107626 Argentina Germany 3.0
59 Ghana Uruguay 47.702576 Uruguay draw 1.0
60 Brazil Netherlands 49.262939 Netherlands Netherlands 0.0
61 Portugal Spain 11.149447 Spain Spain 0.0
62 Japan Paraguay 22.665241 Paraguay draw 1.0
63 Chile Brazil 34.753812 Brazil Brazil 0.0
64 Slovakia Netherlands 17.862216 Netherlands Netherlands 0.0
65 Mexico Argentina 19.963579 Argentina Argentina 0.0
66 England Germany 19.612815 Germany Germany 0.0
67 Ghana USA 70.369020 Ghana Ghana 3.0
68 South Korea Uruguay 27.634301 Uruguay Uruguay 0.0
69 Brazil Portugal 77.683818 Brazil draw 1.0
70 Germany Ghana 73.474151 Germany Germany 3.0
71 Serbia Australia 31.253679 Australia Australia 0.0
72 Côte d'Ivoire Brazil 16.341842 Brazil Brazil 0.0
73 Australia Ghana 38.165116 Ghana draw 1.0
74 Japan Netherlands 6.998814 Netherlands Netherlands 0.0
75 Serbia Germany 6.130914 Germany Serbia 3.0
76 Mexico France 52.503379 Mexico Mexico 3.0
77 South Korea Argentina 14.223277 Argentina Argentina 0.0
78 Switzerland Spain 15.908251 Spain Switzerland 3.0
79 Portugal Côte d'Ivoire 69.916891 Portugal draw 1.0
80 Paraguay Italy 43.871427 Italy draw 1.0
81 Australia Germany 16.694780 Germany Germany 0.0
82 Ghana Serbia 85.417376 Ghana Ghana 3.0
83 USA England 52.553244 USA draw 1.0
84 France Italy 34.562803 Italy draw 1.0
85 Portugal Germany 16.075847 Germany Germany 0.0
86 France Portugal 56.422181 France France 3.0
87 Italy Germany 21.500138 Germany Italy 3.0
88 France Brazil 23.160437 Brazil France 3.0
89 Portugal England 52.083159 Portugal draw 1.0
90 Ukraine Italy 26.756031 Italy Italy 0.0
91 Argentina Germany 41.445493 Germany draw 1.0
92 France Spain 20.617480 Spain France 3.0
93 Ghana Brazil 16.941207 Brazil Brazil 0.0
94 Ukraine Switzerland 48.073103 Switzerland draw 1.0
95 Australia Italy 22.532935 Italy Italy 0.0
96 Netherlands Portugal 75.542414 Netherlands Portugal 0.0
97 Ecuador England 39.677182 England England 0.0
98 Mexico Argentina 31.243456 Argentina Argentina 0.0
99 Sweden Germany 8.403587 Germany Germany 0.0
Helper codes are under features.py, matchstats.py, [power.py)(power.py), worldcup.py
Kaynaklar
[1] Google Cloud Platform Blog, Google Cloud Platform goes 8 for 8 in World Cup predictions, http://googlecloudplatform.blogspot.de/2014/07/google-cloud-platform-goes-8-for-8-in-soccer-predictions.html
[2] Google Cloud Platform, Sample iPython notebook with soccer predictions, https://github.com/GoogleCloudPlatform/ipython-soccer-predictions
[3] Google, Predicting the World Cup with the Google Cloud Platform, http://nbviewer.ipython.org/github/GoogleCloudPlatform/ipython-soccer-predictions/blob/master/predict/wc-final.ipynb
Yukarı